Google

Recherche personnalisée
Connexion
Qui est en ligne ?
Il y a en tout 5 utilisateurs en ligne :: 0 Enregistré, 0 Invisible et 5 Invités :: 1 Moteur de rechercheAucun
Le record du nombre d'utilisateurs en ligne est de 53 le Jeu 15 Aoû - 21:39
Meilleurs posteurs
| Cendrillon | ||||
| dragoun | ||||
| moh748 | ||||
| ThE RiadH | ||||
| necropathologist7 | ||||
| onlystyle | ||||
| Carlo | ||||
| nanoussa | ||||
| desmond | ||||
| Imperial Phoenix |
Marque-page social



Statistiques
Nous avons 1379 membres enregistrésL'utilisateur enregistré le plus récent est gusgus
Nos membres ont posté un total de 22812 messages dans 1131 sujets
Meteo
Flux 

Découverte de connaissance a partir des données
2 participants
Page 1 sur 1

Découverte de connaissance a partir des données
par fatehdz Lun 20 Juil - 16:46
Salam,
Je vais reprendre ici des notes d'un cour appelé "Découverte de connaissance à partir des données"
Ces notes de cours correspond à une partie d'un cours donné en IUP MIAG 3 année à LILE 1 et en Maitrise MASS (Math appliquée au science sociale) à Lile3
Donné par Rémi Gilleron et Marc Tommassi
Le but de ce cours et présenter des outils, des techniques liées à l'informatique décisionnelle. De l'entrepôt de données qui définit un support au système d'information décisionnel, aux outils de fouille de données permettant d'extraire de nouvelles connaissance, ces dernières sont issus de 3 grand domaine, La Statistique, L'intelligence artificielle (ensemble d'algorithmes dédié à l'apprentissage à partir des données), l'informatique (SGBD, Entrepot de donnée).
La connaissance de ce domaine est très importante voir même indispensable pour tous statisticien, quelque soit la spécialité qu'il choisis. En effet dans la plupart des formations universitaire en statistique, des modules d'informatique décisionnelle sont enseigné, voir même des spécialité entière sont dédié à ce domaine. Et vue que notre institut n'enseigne pas ce genre de module, j'ai eut l'idée de présenter ce cours ici dans le forum, je vous demande de participer pleinement au sujet et de poser vos questions, je ferais plaisir de vos répondre.
Après la fin de ce cour inchallah, vous aurez tous pas mal de connaissance théorique, et comme c'est un domaine très intéressant vous aurez certainement envie de de pratiquer un peu le décisionnelle, ce que nous allons faire ensemble.
Pour le moment j'apprend a travailler avec certains logiciel qui permettent de faire du décisionnelle et du DataMining, d'ici la fin du cour je crois que j'aurais pu appliqué qlq cas pratiques que j'aurais plaisir de vous les montrer. et qui sait peut être que qlqn d'entre vous aimeras ce domaine et décideras de qu'il seras le sujet de son mémoire.
Avant de commencer je vous demande encore une fois de participer pleinement à la réussite de cette initiative, car vous n'avez pas le regretter inchallah
Je vais reprendre ici des notes d'un cour appelé "Découverte de connaissance à partir des données"
Ces notes de cours correspond à une partie d'un cours donné en IUP MIAG 3 année à LILE 1 et en Maitrise MASS (Math appliquée au science sociale) à Lile3
Donné par Rémi Gilleron et Marc Tommassi
Le but de ce cours et présenter des outils, des techniques liées à l'informatique décisionnelle. De l'entrepôt de données qui définit un support au système d'information décisionnel, aux outils de fouille de données permettant d'extraire de nouvelles connaissance, ces dernières sont issus de 3 grand domaine, La Statistique, L'intelligence artificielle (ensemble d'algorithmes dédié à l'apprentissage à partir des données), l'informatique (SGBD, Entrepot de donnée).
La connaissance de ce domaine est très importante voir même indispensable pour tous statisticien, quelque soit la spécialité qu'il choisis. En effet dans la plupart des formations universitaire en statistique, des modules d'informatique décisionnelle sont enseigné, voir même des spécialité entière sont dédié à ce domaine. Et vue que notre institut n'enseigne pas ce genre de module, j'ai eut l'idée de présenter ce cours ici dans le forum, je vous demande de participer pleinement au sujet et de poser vos questions, je ferais plaisir de vos répondre.
Après la fin de ce cour inchallah, vous aurez tous pas mal de connaissance théorique, et comme c'est un domaine très intéressant vous aurez certainement envie de de pratiquer un peu le décisionnelle, ce que nous allons faire ensemble.
Pour le moment j'apprend a travailler avec certains logiciel qui permettent de faire du décisionnelle et du DataMining, d'ici la fin du cour je crois que j'aurais pu appliqué qlq cas pratiques que j'aurais plaisir de vous les montrer. et qui sait peut être que qlqn d'entre vous aimeras ce domaine et décideras de qu'il seras le sujet de son mémoire.
Avant de commencer je vous demande encore une fois de participer pleinement à la réussite de cette initiative, car vous n'avez pas le regretter inchallah

fatehdz- Bavard

-

Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Lun 20 Juil - 17:36
Programme
Introduction
1 Entrepôts de données
1.1 Informatique décisionnelle vs Informatique de Production
1.2 Construction d'un Entrepôt
1.2.1 Étude préalable
1.2.1 Modèles de données
1.2.3 Alimentation
1.3 Utilisation, exploitation
1.3.1 Requêtes
1.3.2 Agrégats et navigation.
1.3.3 Visualisation
1.3.4 Supports physique, optimisations.
2 Processus de découverte d'information
2.1 Préparation des données
2.2 Nettoyage
2.3 Enrichissement
2.4 Codage, normalisation
2.5 Fouille
2.6 Validation
3 Fouille de données
3.1 Généralités
3.2 Un algorithme pour la segmentation
3.3 Les règles d'association
3.4 Les plus proches voisins
3.5 Les arbres de décision
3.6 Les réseaux de neurones
Un programme assez riche qu'on va découvrir ensemble
Introduction
1 Entrepôts de données
1.1 Informatique décisionnelle vs Informatique de Production
1.2 Construction d'un Entrepôt
1.2.1 Étude préalable
1.2.1 Modèles de données
1.2.3 Alimentation
1.3 Utilisation, exploitation
1.3.1 Requêtes
1.3.2 Agrégats et navigation.
1.3.3 Visualisation
1.3.4 Supports physique, optimisations.
2 Processus de découverte d'information
2.1 Préparation des données
2.2 Nettoyage
2.3 Enrichissement
2.4 Codage, normalisation
2.5 Fouille
2.6 Validation
3 Fouille de données
3.1 Généralités
3.2 Un algorithme pour la segmentation
3.3 Les règles d'association
3.4 Les plus proches voisins
3.5 Les arbres de décision
3.6 Les réseaux de neurones
Un programme assez riche qu'on va découvrir ensemble
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par Les_Zommes Lun 20 Juil - 17:37
interessant !! fai nou plaisir et pass les intro !! bah alors t'attend koi !! vasy less moi absrobé ton savoir chui en mank c jour si !!

Les_Zommes- Bavard
-
Nombre de messages : 223
Age : 36
Date d'inscription : 18/12/2007
Re: Découverte de connaissance a partir des données
par fatehdz Lun 20 Juil - 18:00
L'informatique de gestion a gagné sa place dans l'entreprise depuis les années 60 par une succession de progrès technologiques, logiciels et méthodologiques qui ont tous contribué à une réduction des coûts d'exploitation. L'invention du compilateur et de la compatibilité des séries de machines dans les années 60 a permis aux grands comptes de s'équiper. Le microprocesseur et les bases de données dans les années 70 ont rendu l'informatisation accessible aux moyennes et grandes entreprises. Les bases de données relationnelles, les progiciels de gestion, ainsi que les premiers micro-ordinateurs des années 80 ont largement contribué à l'équipement des petites et moyennes entreprises, commerces, administrations. Jusque là, la plus grande partie des applications était dédiée au traitement des données directement liées à l'activité quotidienne des organisations : paie, comptabilité, commandes, facturation, ...Ces applications que l'on regroupe sous le terme d'informatique de production ou Informatique Opérationnelle. L'architecture générale était l'architecture maître-esclave, avec le maître, un puissant ordinateur (mini, ou gros système) en site central et les esclaves, terminaux passifs en mode texte. L'organisation de l'entreprise était très hiérarchisée dans sa structure informatique et sa structure de pilotage. Si des techniques d'aide à la décision ont été mises en place (essentiellement basées sur des outils de simulation et d'optimisation, parfois aussi de systèmes experts), elles nécessitaient l'intervention d'équipes d'informaticiens pour le développement de produits spécifiques. Ces outils étaient mal intégrés dans le système d'information.
Avec l'apparition des ordinateurs personnels et des réseaux locaux, une autre activité a émergé, tout à fait distincte de l'informatique de production. Dans les secrétariats, les cabinets, on utilise des tableurs et des logiciels de traitements de texte, des petites bases de données sur des machines aux interfaces graphiques plus agréables. Jusqu'aux années 90, ces deux mondes (<< bureautique vs informatique >>) se sont ignorés, mais avec la montée en puissance des micro ordinateurs et l'avènement de l'architecture client-serveur, on observe aujourd'hui un décloisonnement remarquable. Le mot d'ordre principal est :
fournir à tout utilisateur reconnu et autorisé, les informations nécessaires à son travail.
Ce slogan fait naître une nouvelle informatique, intégrante, orientée vers les utilisateurs et les centres de décision des organisations. C'est l'ère du client-serveur qui prend vraiment tout son essor à la fin des années 90 avec le développement des technologies Intranet.
Enfin, un environnement de concurrence plus pressant contribue à révéler l'informatique décisionnelle. Tout utilisateur de l'entreprise ayant à prendre des décisions doit pouvoir accéder en temps réel aux données de l'entreprise, doit pouvoir traiter ces données, extraire l'information pertinente de ces données pour prendre les << bonnes >> décisions. Il se pose des questions du type : << quels sont les résultats des ventes par gamme de produit et par région pour l'année dernière ? >> ; << Quelle est l'évolution des chiffres d'affaires par type de magasin et par période >> ; ou encore << Comment qualifier les acheteurs de mon produit X ? >> ...Le système opérationnel ne peut satisfaire ces besoins pour au moins deux raisons : les bases de données opérationnelles sont trop complexes pour pouvoir être appréhendées facilement par tout utilisateur et le système opérationnel ne peut être interrompu pour répondre à des questions nécessitant des calculs importants. Il s'avère donc nécessaire de développer des systèmes d'information orientés vers la décision. Il faut garder un historique et restructurer les données de production, éventuellement récupérer des informations démographiques, géographiques et sociologiques. Les entrepôts de données ou datawarehouse sont la réalisation de ces nouveaux systèmes d'information. De nouveau, cette apparition est rendue possible grâce aux progrès technologiques à coûts constants (grâce à l'augmentation importante des capacités de stockage et à l'introduction des techniques du parallélisme dans l'informatique de gestion, techniques qui permettent des accès rapides à de grandes bases de données).
L'informatique décisionnelle s'est développée dans les années 70. Elle est alors essentiellement constituée d'outils d'édition de rapports, de statistiques, de simulation et d'optimisation. Provenant des recherches en Intelligence Artificielle, les systèmes experts apparaissent. Ils sont conçus par << extraction >> de la connaissance d'un ou plusieurs experts et sont des systèmes à base de règles. De bons résultats sont obtenus pour certains domaines d'application tels que la médecine, la géologie, la finance, ... Cependant, il apparaît vite que la formalisation sous forme de règles de la prise de décision est une tâche difficile voire impossible dans de nombreux domaines. Dans les années 90, deux phénomènes se produisent simultanément. Premièrement, comme nous l'avons montré dans les paragraphes précédents, il est possible de concevoir des environnements spécialisés pour l'aide à la décision. Deuxièmement, de nombreux algorithmes permettant d'extraire des informations à partir de données brutes sont arrivés à maturité. Ces algorithmes ont des origines diverses et souvent multiples. Certains sont issus des statistiques ; d'autres proviennent des recherches en Intelligence Artificielle, recherches qui se sont concentrées sur des projets moins ambitieux, plus ciblés ; certains s'inspirent de phénomèmes biologiques ou de la théorie de l'évolution. Tous ces algorithmes sont regroupés dans des logiciels de fouille de données ou Data Mining qui permettent la recherche d'informations nouvelles ou cachées à partir de données. Ainsi, dans le cas de systèmes à base de règles, plutôt que d'essayer d'extraire la connaissance d'experts et d'exprimer cette connaissance sous forme de règles, un logiciel va générer ces règles à partir de données. Par exemple, à partir d'un fichier historique des prêts contenant des renseignements sur les clients et le résultat du prêt (problèmes de recouvrement ou pas), le logiciel extrait un profil pour désigner un << bon >> ou un << mauvais >> client. Après validation, un tel système peut être implanté dans le système d'information de l'entreprise afin de << classer >> ou de << noter >> les nouveaux clients.
Plusieurs méthodes existent pour mettre en oeuvre la fouille de données. Le choix de l'une d'entre elles est une première difficulté pour l'utilisateur ou le concepteur. Aucune méthode n'est meilleure qu'une autre dans l'absolu. Néanmoins, l'environnement, les contraintes, les objectifs et bien sûr les propriétés des méthodes doivent guider l'utilisateur dans son choix.
Les entrepôts de données et la fouille de données sont les éléments d'un domaine de recherche et de développement très actifs actuellement : l'extraction de connaissances à partir de données ou Knowedge Discovery in Databases (KDD for short). Par ce terme, on désigne tout le cycle de découverte d'information. Il regroupe donc la conception et les accès à de grandes bases de données ; tous les traitements à effectuer pour extraire de l'information de ces données ; l'un de ces traitements est l'étape de fouille de données ou Data Mining. C'est l'objectif de ce cours que de vous en présenter les éléments essentiels.
Le plan de ce cours est le suivant :
* un premier chapitre présente les entrepôts de données (chapitre 1) en insistant sur les différences entre un tel système et les bases de données opérationnelles et transactionnelles ; en présentant des éléments méthodologiques pour la conception d'entrepôts de données, les modèles de données correspondants, les problèmes liés à l'alimentation de ces entrepôts, et quelques éléments d'information sur les technologies qui optimisent les accès à de tels systèmes.
* Un second chapitre (chapitre 2) présente le cycle complet de découverte d'informations à partir de données (Knowledge Discovery in Databases) : la préparation des données, le nettoyage, l'enrichissement, le codage et la normalisation, la fouille de données, la validation et l'intégration dans le système d'information.
* Le dernier chapitre porte une attention particulière sur la fouille de données (chapitre 3). Il est hors d'atteinte d'un tel cours de prétendre présenter toutes les techniques disponibles. Nous présentons la base des méthodes les plus classiques : l'algorithme des k-moyennes, les règles d'association, la méthode des plus proches voisins, les arbres de décision et les réseaux de neurones.
Nous recommandons essentiellement la lecture des ouvrages suivants :
* le livre de P. Adriaans et D. Zantinge [AZ96], remarquable par sa clarté, qui présente la découverte de connaissances à partir de données ;
* le livre de R. Kimball [Kim97] sur les entrepôts de données ; le livre contient de nombreux exemples ;
* le livre de M. Berry et G. Linoff [BL97] qui présente, en contexte d'applications et clairement, les méthodes de fouille de données ;
* pour ceux qui seraient plus intéressés par les aspects algorithmiques et l'apprentissage automatique, l'ouvrage de T. Mitchell [Mit97] est, en tous points, exceptionnel. Pour les aspects classification supervisée, il est possible également de consulter le poly de F. Denis et R. Gilleron [DG99] qui contient de nombreux exercices.
Avec l'apparition des ordinateurs personnels et des réseaux locaux, une autre activité a émergé, tout à fait distincte de l'informatique de production. Dans les secrétariats, les cabinets, on utilise des tableurs et des logiciels de traitements de texte, des petites bases de données sur des machines aux interfaces graphiques plus agréables. Jusqu'aux années 90, ces deux mondes (<< bureautique vs informatique >>) se sont ignorés, mais avec la montée en puissance des micro ordinateurs et l'avènement de l'architecture client-serveur, on observe aujourd'hui un décloisonnement remarquable. Le mot d'ordre principal est :
fournir à tout utilisateur reconnu et autorisé, les informations nécessaires à son travail.
Ce slogan fait naître une nouvelle informatique, intégrante, orientée vers les utilisateurs et les centres de décision des organisations. C'est l'ère du client-serveur qui prend vraiment tout son essor à la fin des années 90 avec le développement des technologies Intranet.
Enfin, un environnement de concurrence plus pressant contribue à révéler l'informatique décisionnelle. Tout utilisateur de l'entreprise ayant à prendre des décisions doit pouvoir accéder en temps réel aux données de l'entreprise, doit pouvoir traiter ces données, extraire l'information pertinente de ces données pour prendre les << bonnes >> décisions. Il se pose des questions du type : << quels sont les résultats des ventes par gamme de produit et par région pour l'année dernière ? >> ; << Quelle est l'évolution des chiffres d'affaires par type de magasin et par période >> ; ou encore << Comment qualifier les acheteurs de mon produit X ? >> ...Le système opérationnel ne peut satisfaire ces besoins pour au moins deux raisons : les bases de données opérationnelles sont trop complexes pour pouvoir être appréhendées facilement par tout utilisateur et le système opérationnel ne peut être interrompu pour répondre à des questions nécessitant des calculs importants. Il s'avère donc nécessaire de développer des systèmes d'information orientés vers la décision. Il faut garder un historique et restructurer les données de production, éventuellement récupérer des informations démographiques, géographiques et sociologiques. Les entrepôts de données ou datawarehouse sont la réalisation de ces nouveaux systèmes d'information. De nouveau, cette apparition est rendue possible grâce aux progrès technologiques à coûts constants (grâce à l'augmentation importante des capacités de stockage et à l'introduction des techniques du parallélisme dans l'informatique de gestion, techniques qui permettent des accès rapides à de grandes bases de données).
L'informatique décisionnelle s'est développée dans les années 70. Elle est alors essentiellement constituée d'outils d'édition de rapports, de statistiques, de simulation et d'optimisation. Provenant des recherches en Intelligence Artificielle, les systèmes experts apparaissent. Ils sont conçus par << extraction >> de la connaissance d'un ou plusieurs experts et sont des systèmes à base de règles. De bons résultats sont obtenus pour certains domaines d'application tels que la médecine, la géologie, la finance, ... Cependant, il apparaît vite que la formalisation sous forme de règles de la prise de décision est une tâche difficile voire impossible dans de nombreux domaines. Dans les années 90, deux phénomènes se produisent simultanément. Premièrement, comme nous l'avons montré dans les paragraphes précédents, il est possible de concevoir des environnements spécialisés pour l'aide à la décision. Deuxièmement, de nombreux algorithmes permettant d'extraire des informations à partir de données brutes sont arrivés à maturité. Ces algorithmes ont des origines diverses et souvent multiples. Certains sont issus des statistiques ; d'autres proviennent des recherches en Intelligence Artificielle, recherches qui se sont concentrées sur des projets moins ambitieux, plus ciblés ; certains s'inspirent de phénomèmes biologiques ou de la théorie de l'évolution. Tous ces algorithmes sont regroupés dans des logiciels de fouille de données ou Data Mining qui permettent la recherche d'informations nouvelles ou cachées à partir de données. Ainsi, dans le cas de systèmes à base de règles, plutôt que d'essayer d'extraire la connaissance d'experts et d'exprimer cette connaissance sous forme de règles, un logiciel va générer ces règles à partir de données. Par exemple, à partir d'un fichier historique des prêts contenant des renseignements sur les clients et le résultat du prêt (problèmes de recouvrement ou pas), le logiciel extrait un profil pour désigner un << bon >> ou un << mauvais >> client. Après validation, un tel système peut être implanté dans le système d'information de l'entreprise afin de << classer >> ou de << noter >> les nouveaux clients.
Plusieurs méthodes existent pour mettre en oeuvre la fouille de données. Le choix de l'une d'entre elles est une première difficulté pour l'utilisateur ou le concepteur. Aucune méthode n'est meilleure qu'une autre dans l'absolu. Néanmoins, l'environnement, les contraintes, les objectifs et bien sûr les propriétés des méthodes doivent guider l'utilisateur dans son choix.
Les entrepôts de données et la fouille de données sont les éléments d'un domaine de recherche et de développement très actifs actuellement : l'extraction de connaissances à partir de données ou Knowedge Discovery in Databases (KDD for short). Par ce terme, on désigne tout le cycle de découverte d'information. Il regroupe donc la conception et les accès à de grandes bases de données ; tous les traitements à effectuer pour extraire de l'information de ces données ; l'un de ces traitements est l'étape de fouille de données ou Data Mining. C'est l'objectif de ce cours que de vous en présenter les éléments essentiels.
Le plan de ce cours est le suivant :
* un premier chapitre présente les entrepôts de données (chapitre 1) en insistant sur les différences entre un tel système et les bases de données opérationnelles et transactionnelles ; en présentant des éléments méthodologiques pour la conception d'entrepôts de données, les modèles de données correspondants, les problèmes liés à l'alimentation de ces entrepôts, et quelques éléments d'information sur les technologies qui optimisent les accès à de tels systèmes.
* Un second chapitre (chapitre 2) présente le cycle complet de découverte d'informations à partir de données (Knowledge Discovery in Databases) : la préparation des données, le nettoyage, l'enrichissement, le codage et la normalisation, la fouille de données, la validation et l'intégration dans le système d'information.
* Le dernier chapitre porte une attention particulière sur la fouille de données (chapitre 3). Il est hors d'atteinte d'un tel cours de prétendre présenter toutes les techniques disponibles. Nous présentons la base des méthodes les plus classiques : l'algorithme des k-moyennes, les règles d'association, la méthode des plus proches voisins, les arbres de décision et les réseaux de neurones.
Nous recommandons essentiellement la lecture des ouvrages suivants :
* le livre de P. Adriaans et D. Zantinge [AZ96], remarquable par sa clarté, qui présente la découverte de connaissances à partir de données ;
* le livre de R. Kimball [Kim97] sur les entrepôts de données ; le livre contient de nombreux exemples ;
* le livre de M. Berry et G. Linoff [BL97] qui présente, en contexte d'applications et clairement, les méthodes de fouille de données ;
* pour ceux qui seraient plus intéressés par les aspects algorithmiques et l'apprentissage automatique, l'ouvrage de T. Mitchell [Mit97] est, en tous points, exceptionnel. Pour les aspects classification supervisée, il est possible également de consulter le poly de F. Denis et R. Gilleron [DG99] qui contient de nombreux exercices.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Lun 20 Juil - 18:07
Chapitre 1 Entrepôts de données
* Informatique décisionnelle vs Informatique de production
* Construction d'un entrepôt
* Utilisation, exploitation
Un métier du secteur informatique a certainement déjà disparu : monteur de bandes. Cette personne était chargée de manutentionner des bandes magnétiques depuis les lieux de stockage jusqu'au site informatique central ou trônait un gigantesque ordinateur avec ses lecteurs de bande comme seule unité de sauvegarde. Pour charger une nouvelle application, il fallait monter la bande correspondante dans cette armoire où l'on voyait deux disques tourner, s'arrêter, changer de sens etc. Ce précieux périphérique remplaçait avantageusement les lecteurs de cartes trop lents. Mais l'apparition du disque dur, d'une remarquable capacité de 5Mo, a envoyé la bande à la décharge au milieu des années 80. Aujourd'hui, le Mo est l'unité pour la mémoire vive et nous produisons des machines stockant plusieurs PetaOctets (des millions de milliards d'octets). Ce besoin de stockage est-il justifié et en quoi est-il nécessaire ?
Les sociétés de téléphone gardent au moins un an les positions géographiques et les consommations de leurs abonnés << mobiles >>. Les grands magasins et les entreprises de vente par correspondance (VPC) conservent les achats de leurs clients (tickets de caisse en grande distribution, commandes en VPC), collectent des informations sur leurs clients grâce à des systèmes de cartes de fidélité ou de crédit, et achètent des bases de données géographiques et démographiques. Les sites web conservent des traces de connexions sur leurs sites marchands. En résumé, les entreprises en secteur très concurrentiel conservent les données de leur activité et achètent même des données.
Les motifs qui ont présidé à la conservation de ces données étaient : des obligations légales pour pouvoir justifier les facturations, des raisons de sécurité pour pouvoir détecter les fraudes, des motifs commerciaux pour suivre l'évolution des clients et des marchés. Quelle que soit la raison initiale, les entreprises se sont rendues compte que ces données pouvaient être une source d'informations à leur service. Ce constat, valable pour les sociétés du secteur marchand, peut être étendu à de nombreux domaines comme la médecine, la pharmacologie. Il faut donc définir des environnements permettant de mémoriser de grands jeux de données et d'en extraire de l'information.
Les structures qui accueillent ce flot important de données sont des entrepôts de données ou data warehouse. Ils sont construits sur une nouvelle architecture permettant d'extraire l'information, architecture bien différente de celle prévue pour l'informatique de production, basée elle sur des systèmes de gestion de bases de données relationnelles et des serveurs transactionnels. Un entrepôt de données est construit en l'alimentant via les serveurs transactionnels de façon bien choisie et réfléchie pour permettre aux procédures d'extraction de connaissances de bien fonctionner. L'organisation logique des données est particulièrement conçue pour autoriser des recherches complexes. Le matériel est évidemment adapté à cette utilisation.
Nous rappelons les différences essentielles entre informatique de production et de décision (section 1.1). La phase de construction est abordée en section 1.2. Nous la présentons en trois parties : l'étude préalable qui étudie la faisabilité, les besoins ; l'étude des données et de leur modélisation ; l'étude de l'alimentation l'entrepôt. Le chapitre se termine par une présentation rapide des outils d'exploitation et d'administration : navigation, optimisation, requêtes et visualisation (section 1.3).
* Informatique décisionnelle vs Informatique de production
* Construction d'un entrepôt
* Utilisation, exploitation
Un métier du secteur informatique a certainement déjà disparu : monteur de bandes. Cette personne était chargée de manutentionner des bandes magnétiques depuis les lieux de stockage jusqu'au site informatique central ou trônait un gigantesque ordinateur avec ses lecteurs de bande comme seule unité de sauvegarde. Pour charger une nouvelle application, il fallait monter la bande correspondante dans cette armoire où l'on voyait deux disques tourner, s'arrêter, changer de sens etc. Ce précieux périphérique remplaçait avantageusement les lecteurs de cartes trop lents. Mais l'apparition du disque dur, d'une remarquable capacité de 5Mo, a envoyé la bande à la décharge au milieu des années 80. Aujourd'hui, le Mo est l'unité pour la mémoire vive et nous produisons des machines stockant plusieurs PetaOctets (des millions de milliards d'octets). Ce besoin de stockage est-il justifié et en quoi est-il nécessaire ?
Les sociétés de téléphone gardent au moins un an les positions géographiques et les consommations de leurs abonnés << mobiles >>. Les grands magasins et les entreprises de vente par correspondance (VPC) conservent les achats de leurs clients (tickets de caisse en grande distribution, commandes en VPC), collectent des informations sur leurs clients grâce à des systèmes de cartes de fidélité ou de crédit, et achètent des bases de données géographiques et démographiques. Les sites web conservent des traces de connexions sur leurs sites marchands. En résumé, les entreprises en secteur très concurrentiel conservent les données de leur activité et achètent même des données.
Les motifs qui ont présidé à la conservation de ces données étaient : des obligations légales pour pouvoir justifier les facturations, des raisons de sécurité pour pouvoir détecter les fraudes, des motifs commerciaux pour suivre l'évolution des clients et des marchés. Quelle que soit la raison initiale, les entreprises se sont rendues compte que ces données pouvaient être une source d'informations à leur service. Ce constat, valable pour les sociétés du secteur marchand, peut être étendu à de nombreux domaines comme la médecine, la pharmacologie. Il faut donc définir des environnements permettant de mémoriser de grands jeux de données et d'en extraire de l'information.
Les structures qui accueillent ce flot important de données sont des entrepôts de données ou data warehouse. Ils sont construits sur une nouvelle architecture permettant d'extraire l'information, architecture bien différente de celle prévue pour l'informatique de production, basée elle sur des systèmes de gestion de bases de données relationnelles et des serveurs transactionnels. Un entrepôt de données est construit en l'alimentant via les serveurs transactionnels de façon bien choisie et réfléchie pour permettre aux procédures d'extraction de connaissances de bien fonctionner. L'organisation logique des données est particulièrement conçue pour autoriser des recherches complexes. Le matériel est évidemment adapté à cette utilisation.
Nous rappelons les différences essentielles entre informatique de production et de décision (section 1.1). La phase de construction est abordée en section 1.2. Nous la présentons en trois parties : l'étude préalable qui étudie la faisabilité, les besoins ; l'étude des données et de leur modélisation ; l'étude de l'alimentation l'entrepôt. Le chapitre se termine par une présentation rapide des outils d'exploitation et d'administration : navigation, optimisation, requêtes et visualisation (section 1.3).
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Lun 20 Juil - 18:26
1.1 Informatique décisionnelle vs Informatique de production
Une des principales caractéristiques des systèmes de production est une activité constante constituée de modifications et d'interrogations fréquentes des données par de nombreux utilisateurs : ajouter une commande, modifier une adresse de livraison, rechercher les coordonnées d'un client, ... Il faut conserver la cohérence des données (il faut interdire la modification simultanée d'une même donnée par deux utilisateurs différents). Il s'agit donc de privilégier un enregistrement rapide et sûr des données. À l'inverse, les utilisateurs des systèmes d'information de décision n'ont aucun besoin de modification ou d'enregistrement de nouvelles données. Ils vont interroger le système d'information et les questions posées seront de la forme : << quelles sont les ventes du produit X pendant le trimestre A de l'année B dans la région C >>. Une telle interrogation peut nécessiter des temps de calcul importants. Or, l'activité d'un serveur transactionnel ne peut être interrompue. Il faut donc prévoir une nouvelle organisation qui permette de mémoriser de grands jeux de données et qui facilite la recherche d'informations.
Enfin, nous étudierons dans le chapitre suivant l'extraction de connaissances à partir de données. Les méthodes de fouille de données nécessitent une préparation et une organisation particulière des données que nous détaillerons au chapitre suivant. L'existence d'un entrepôt simplifiera cette tâche et permettra donc d'optimiser le temps de développement d'un projet d'extraction de connaissances. En résumé, on peut justifier la construction d'un entrepôt de données par l'affirmation suivante :
il est beaucoup plus simple de trouver une information pertinente dans une structure organisée pour la recherche de connaissance.
La production
Le modèle Entité-Association (ou modèle EA) est l'un des formalismes les plus utilisés pour la représentation conceptuelle des systèmes d'information. Il permet de construire des modèles de données dans lesquels on cherche à tout prix à éviter des redondances. Toute donnée mémorisée plus d'une fois est source d'erreurs, d'incohérences, et va pénaliser les temps d'exécution et complexifier les procédures d'ajout, de suppression ou de modification.
D'un point de vue logique, ce sont les bases de données relationnelles qui ont su au mieux représenter ces modèles conceptuels. Les éditeurs de logiciels et les architectes d'ordinateurs ont dû fournir un effort important pour les rendre efficaces. Aujourd'hui les bases relationnelles ont acquis une maturité satisfaisante pour être largement utilisées et diffusées dans de nombreuses organisations, à toute échelle.
Conserver la cohérence de la base de données, c'est l'objectif et la difficulté principale pour l'informatique de production. Les systèmes transactionnels (temps réel) OLTP (On-Line Transaction Processing) garantissent l'intégrité des données. Les utilisateurs accèdent à des éléments de la base par de très courtes transactions indécomposables, isolées. Ils y accèdent très souvent pour des opérations d'ajout, suppression, modification mais aussi de lecture. L'isolation permet de garantir que la transaction ne sera pas perturbée ni interrompue. Les contrôles effectués sont élémentaires. La brièveté garantit que les temps de réponse seront acceptables (inférieurs à la seconde) dans un environnement avec de nombreux utilisateurs.
Bien sûr, dans le souci de la garantie des performances, une requête dont le calcul prendrait trop de temps est inacceptable. Par exemple, une jointure sur de grosses tables à l'aide de champs non indexés est interdite. Les travaux sur une telle base sont souvent simples et répétitifs. Dès lors qu'un travail plus important est nécessaire, l'intervention de programmeurs et d'administrateurs de la base est requise et une procédure ad-hoc est créée et optimisée.
Le modèle Entité-Association et sa réalisation dans un schéma relationnel sont pourtant des obstacles importants pour l'accès de l'utilisateur final aux données. Dans une situation réelle, le modèle des données est très large et contient plusieurs dizaines d'entités. Les bases sont alors constituées de nombreuses tables, reliées entre elles par divers liens dont le sens n'est pas toujours explicite. Souvent, les organisations ont choisi une norme pour définir des noms à chaque objet (table, champ,...) très << syntaxiques >> sans sémantique claire. Le but était de faciliter le travail des développeurs et l'efficacité des procédures. L'utilisateur final n'est pas considéré ici car c'est à l'informaticien de lui proposer une abstraction de ces modèles à travers les outils dont il a besoin. La complexité des données, l'absence d'annuaire clair rend la base inutilisable aux non initiés sans l'intervention d'informaticiens et d'outils sur mesure.
L'informatique de production a donc été conçue pour privilégier les performances de tâches répétitives, prévues et planifiées tournées vers la production de documents standards (factures, commandes...). L'intervention de l'utilisateur est guidée à travers des outils spécifiques proposés par une équipe de développeurs.
La dernière caractéristique de ces bases de données est qu'elles conservent l'état instantané du système. Dans la plupart des cas, l'évolution n'est pas conservée. On conserve simplement des versions instantanées pour la reprise en cas de panne et pour des raisons légales.
Le décisionnel
Dans un système d'information décisionnel, l'utilisateur final formulera des questions du type :
* Comment se comporte le produit X par rapport au produit Y ?
* Et par rapport à l'année dernière ?
* Quel type de client peut bien acheter mon produit Z ?
Ces exemples permettent de mettre en évidence les faits suivants :
* les questions doivent pouvoir être formulées dans le langage de l'utilisateur en fonction de son << métier >>, c'est-à-dire de son secteur d'activité (service marketing, service économique, service gestion des ressources humaines, ...) ;
* la prévision des interrogations est difficile car elles sont du ressort de l'utilisateur. De plus, ses questions vont varier selon les réponses obtenues : : si le produit X s'est vendu moins bien que l'année précédente, il va être utile d'en comprendre les raisons et donc de détailler les ventes du produit X (par région, par type de magasin, ...)
* des questions ouvertes (profil client du produit Z) vont nécessiter la mise en place de méthodes d'extraction d'informations.
Ce qui caractérise d'abord les besoins, c'est donc la possibilité de poser une grande variété de questions au système, certaines prévisibles et planifiées comme des tableaux de bord et d'autres imprévisibles. Si des outils d'édition automatiques pré-programmés peuvent être envisagés, il est nécessaire de permettre à l'utilisateur d'effectuer les requêtes qu'il souhaite, par lui-même, sans intervention de programmeurs. Deux contraintes apparaissent alors immédiatement: la simplicité du modèle des données, la performance malgré les grands volumes.
Pour les entrepôts de données, on recherche plus de lisibilité, de simplicité que dans le cas des SGBD. La modélisation introduit les notions de fait et dimension. Les faits correspondent à l'activité de l'entreprise : ce sont les ventes pour une entreprise commerciale, les communications pour une entreprise de télécommunications, ... Les dimensions sont les critères sur lesquels on souhaite évaluer, quantifier, qualifier les faits : les dimensions usuelles sont le temps, le client, le magasin, la région, le produit...
Dans les exemples de requêtes citées au début de ce paragraphe, les faits et les dimensions apparaissent :
* les ventes en fait ;
* les produits, les clients, le temps, le lieu en dimensions.
Il sera souvent nécessaire de filtrer, d'agréger, de compter, sommer et de réaliser quelques statistiques élémentaires (moyenne, écart-type,...). La structure logique doit être prévue pour rendre aussi efficace que possible toutes ces requêtes. Pour y parvenir, on est amené à introduire de la redondance dans les informations stockées en mémorisant des calculs intermédiaires (dans l'exemple, on peut être amené à stocker toutes les sommes de ventes par produit ou par année). On rompt donc avec le principe de non redondance des bases de production.
Si le critère de cohérence semble assuré avec les techniques du transactionnel, cette cohérence est toute relative. Elle se contrôle au niveau de la transaction élémentaire mais pas au niveau global et des activités de l'organisation. Pour les entrepôts, on requiert une cohérence interprétable par l'utilisateur. Par exemple, si les livraisons n'ont pas été toutes saisies dans le système, comment garantir la cohérence de l'état du stock ? Autre, exemple, pour établir un profil client ou étudier les performances d'un magasin, toutes les données utiles le concernant doivent être présentes dans le système, ce que n'assure pas le serveur transactionnel mais que doit assurer le serveur décisionnel.
Les entrepôts de données assureront donc plutôt une cohérence globale des données. Pour cette raison, leur alimentation sera un acte réfléchi et planifié dans le temps. Un grand nombre d'informations sera importé du système transactionnel lorsqu'on aura la garantie que toutes les données nécessaires auront été produites et mémorisées. Les transferts de données du système opérationnel vers le système décisionnel seront réguliers avec une périodicité bien choisie dépendante de l'activité de l'entreprise. Chaque transfert sera contrôlé avant d'être diffusé.
Une dernière caractéristique importante des entrepôts, qui est aussi une différence fondamentale avec les bases de production, est qu'aucune information n'y est jamais modifiée. En effet, on mémorise toutes les données sur une période donnée et terminée, il n'y aura donc jamais à remettre en cause ces données car toutes les vérifications utiles auront été faites lors de l'alimentation. L'utilisation se résume donc à un chargement périodique, puis à des interrogations non régulières, non prévisibles, parfois longues à exécuter.
Une des principales caractéristiques des systèmes de production est une activité constante constituée de modifications et d'interrogations fréquentes des données par de nombreux utilisateurs : ajouter une commande, modifier une adresse de livraison, rechercher les coordonnées d'un client, ... Il faut conserver la cohérence des données (il faut interdire la modification simultanée d'une même donnée par deux utilisateurs différents). Il s'agit donc de privilégier un enregistrement rapide et sûr des données. À l'inverse, les utilisateurs des systèmes d'information de décision n'ont aucun besoin de modification ou d'enregistrement de nouvelles données. Ils vont interroger le système d'information et les questions posées seront de la forme : << quelles sont les ventes du produit X pendant le trimestre A de l'année B dans la région C >>. Une telle interrogation peut nécessiter des temps de calcul importants. Or, l'activité d'un serveur transactionnel ne peut être interrompue. Il faut donc prévoir une nouvelle organisation qui permette de mémoriser de grands jeux de données et qui facilite la recherche d'informations.
Enfin, nous étudierons dans le chapitre suivant l'extraction de connaissances à partir de données. Les méthodes de fouille de données nécessitent une préparation et une organisation particulière des données que nous détaillerons au chapitre suivant. L'existence d'un entrepôt simplifiera cette tâche et permettra donc d'optimiser le temps de développement d'un projet d'extraction de connaissances. En résumé, on peut justifier la construction d'un entrepôt de données par l'affirmation suivante :
il est beaucoup plus simple de trouver une information pertinente dans une structure organisée pour la recherche de connaissance.
La production
Le modèle Entité-Association (ou modèle EA) est l'un des formalismes les plus utilisés pour la représentation conceptuelle des systèmes d'information. Il permet de construire des modèles de données dans lesquels on cherche à tout prix à éviter des redondances. Toute donnée mémorisée plus d'une fois est source d'erreurs, d'incohérences, et va pénaliser les temps d'exécution et complexifier les procédures d'ajout, de suppression ou de modification.
D'un point de vue logique, ce sont les bases de données relationnelles qui ont su au mieux représenter ces modèles conceptuels. Les éditeurs de logiciels et les architectes d'ordinateurs ont dû fournir un effort important pour les rendre efficaces. Aujourd'hui les bases relationnelles ont acquis une maturité satisfaisante pour être largement utilisées et diffusées dans de nombreuses organisations, à toute échelle.
Conserver la cohérence de la base de données, c'est l'objectif et la difficulté principale pour l'informatique de production. Les systèmes transactionnels (temps réel) OLTP (On-Line Transaction Processing) garantissent l'intégrité des données. Les utilisateurs accèdent à des éléments de la base par de très courtes transactions indécomposables, isolées. Ils y accèdent très souvent pour des opérations d'ajout, suppression, modification mais aussi de lecture. L'isolation permet de garantir que la transaction ne sera pas perturbée ni interrompue. Les contrôles effectués sont élémentaires. La brièveté garantit que les temps de réponse seront acceptables (inférieurs à la seconde) dans un environnement avec de nombreux utilisateurs.
Bien sûr, dans le souci de la garantie des performances, une requête dont le calcul prendrait trop de temps est inacceptable. Par exemple, une jointure sur de grosses tables à l'aide de champs non indexés est interdite. Les travaux sur une telle base sont souvent simples et répétitifs. Dès lors qu'un travail plus important est nécessaire, l'intervention de programmeurs et d'administrateurs de la base est requise et une procédure ad-hoc est créée et optimisée.
Le modèle Entité-Association et sa réalisation dans un schéma relationnel sont pourtant des obstacles importants pour l'accès de l'utilisateur final aux données. Dans une situation réelle, le modèle des données est très large et contient plusieurs dizaines d'entités. Les bases sont alors constituées de nombreuses tables, reliées entre elles par divers liens dont le sens n'est pas toujours explicite. Souvent, les organisations ont choisi une norme pour définir des noms à chaque objet (table, champ,...) très << syntaxiques >> sans sémantique claire. Le but était de faciliter le travail des développeurs et l'efficacité des procédures. L'utilisateur final n'est pas considéré ici car c'est à l'informaticien de lui proposer une abstraction de ces modèles à travers les outils dont il a besoin. La complexité des données, l'absence d'annuaire clair rend la base inutilisable aux non initiés sans l'intervention d'informaticiens et d'outils sur mesure.
L'informatique de production a donc été conçue pour privilégier les performances de tâches répétitives, prévues et planifiées tournées vers la production de documents standards (factures, commandes...). L'intervention de l'utilisateur est guidée à travers des outils spécifiques proposés par une équipe de développeurs.
La dernière caractéristique de ces bases de données est qu'elles conservent l'état instantané du système. Dans la plupart des cas, l'évolution n'est pas conservée. On conserve simplement des versions instantanées pour la reprise en cas de panne et pour des raisons légales.
Le décisionnel
Dans un système d'information décisionnel, l'utilisateur final formulera des questions du type :
* Comment se comporte le produit X par rapport au produit Y ?
* Et par rapport à l'année dernière ?
* Quel type de client peut bien acheter mon produit Z ?
Ces exemples permettent de mettre en évidence les faits suivants :
* les questions doivent pouvoir être formulées dans le langage de l'utilisateur en fonction de son << métier >>, c'est-à-dire de son secteur d'activité (service marketing, service économique, service gestion des ressources humaines, ...) ;
* la prévision des interrogations est difficile car elles sont du ressort de l'utilisateur. De plus, ses questions vont varier selon les réponses obtenues : : si le produit X s'est vendu moins bien que l'année précédente, il va être utile d'en comprendre les raisons et donc de détailler les ventes du produit X (par région, par type de magasin, ...)
* des questions ouvertes (profil client du produit Z) vont nécessiter la mise en place de méthodes d'extraction d'informations.
Ce qui caractérise d'abord les besoins, c'est donc la possibilité de poser une grande variété de questions au système, certaines prévisibles et planifiées comme des tableaux de bord et d'autres imprévisibles. Si des outils d'édition automatiques pré-programmés peuvent être envisagés, il est nécessaire de permettre à l'utilisateur d'effectuer les requêtes qu'il souhaite, par lui-même, sans intervention de programmeurs. Deux contraintes apparaissent alors immédiatement: la simplicité du modèle des données, la performance malgré les grands volumes.
Pour les entrepôts de données, on recherche plus de lisibilité, de simplicité que dans le cas des SGBD. La modélisation introduit les notions de fait et dimension. Les faits correspondent à l'activité de l'entreprise : ce sont les ventes pour une entreprise commerciale, les communications pour une entreprise de télécommunications, ... Les dimensions sont les critères sur lesquels on souhaite évaluer, quantifier, qualifier les faits : les dimensions usuelles sont le temps, le client, le magasin, la région, le produit...
Dans les exemples de requêtes citées au début de ce paragraphe, les faits et les dimensions apparaissent :
* les ventes en fait ;
* les produits, les clients, le temps, le lieu en dimensions.
Il sera souvent nécessaire de filtrer, d'agréger, de compter, sommer et de réaliser quelques statistiques élémentaires (moyenne, écart-type,...). La structure logique doit être prévue pour rendre aussi efficace que possible toutes ces requêtes. Pour y parvenir, on est amené à introduire de la redondance dans les informations stockées en mémorisant des calculs intermédiaires (dans l'exemple, on peut être amené à stocker toutes les sommes de ventes par produit ou par année). On rompt donc avec le principe de non redondance des bases de production.
Si le critère de cohérence semble assuré avec les techniques du transactionnel, cette cohérence est toute relative. Elle se contrôle au niveau de la transaction élémentaire mais pas au niveau global et des activités de l'organisation. Pour les entrepôts, on requiert une cohérence interprétable par l'utilisateur. Par exemple, si les livraisons n'ont pas été toutes saisies dans le système, comment garantir la cohérence de l'état du stock ? Autre, exemple, pour établir un profil client ou étudier les performances d'un magasin, toutes les données utiles le concernant doivent être présentes dans le système, ce que n'assure pas le serveur transactionnel mais que doit assurer le serveur décisionnel.
Les entrepôts de données assureront donc plutôt une cohérence globale des données. Pour cette raison, leur alimentation sera un acte réfléchi et planifié dans le temps. Un grand nombre d'informations sera importé du système transactionnel lorsqu'on aura la garantie que toutes les données nécessaires auront été produites et mémorisées. Les transferts de données du système opérationnel vers le système décisionnel seront réguliers avec une périodicité bien choisie dépendante de l'activité de l'entreprise. Chaque transfert sera contrôlé avant d'être diffusé.
Une dernière caractéristique importante des entrepôts, qui est aussi une différence fondamentale avec les bases de production, est qu'aucune information n'y est jamais modifiée. En effet, on mémorise toutes les données sur une période donnée et terminée, il n'y aura donc jamais à remettre en cause ces données car toutes les vérifications utiles auront été faites lors de l'alimentation. L'utilisation se résume donc à un chargement périodique, puis à des interrogations non régulières, non prévisibles, parfois longues à exécuter.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Lun 20 Juil - 18:28
Avant de passer à la construction d'entrepôt, j'ouvre la porte à vos questions concernant les points abordés précédemment si touts est claire, vous ne perdez rien à dire "Oui tout est claire"
Vous pouvez Aussi consulter mon sujet sur la formation Access première partie, ou j'ai expliqué c'est quoi les bases de données relationnelle: https://inps.keuf.net/cours-retranscriptions-f8/apprendre-access-les-tables-t846.htm
Vous pouvez Aussi consulter mon sujet sur la formation Access première partie, ou j'ai expliqué c'est quoi les bases de données relationnelle: https://inps.keuf.net/cours-retranscriptions-f8/apprendre-access-les-tables-t846.htm
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Mar 21 Juil - 16:48
Puisqu'a personne n'a posé de question, cela veut dire soit que personne ne s'intéresse à ce sujet soit que tout est claire, je vais opter pour la deuxième proposition c'est à dire que tout est claire et je vais continuer le cour.
1.2 Construction d'un entrepôt
L'entrepôt de données est donc bien différent des bases de données de production car les besoins pour lesquels on veut le construire sont différents. Il contient des informations historisées, globalement cohérentes, organisées selon les métiers de l'entreprise pour le processus de décision. L'entrepôt n'est pas un produit ou un logiciel mais un environnement. Il se bâtit et ne s'achète pas. Les données sont puisées dans les bases de production, nettoyées, normalisées, puis intégrées. Des métadonnées décrivent les informations dans cette nouvelle base pour lever toute ambiguïté quant à leur origine et leur signification.
Nous décrivons, dans ce chapitre, les problèmes liés à la construction d'un entrepôt, les modèles de données et son alimentation. Mais, il faut garder à l'esprit qu'un entrepôt se conçoit avec un ensemble d'applications qui vont réaliser ce pour quoi il a été construit : l'aide à la décision. Ce sont des outils d'accès aux données (requêteurs, visualisateurs, outils de fouille, ...) qui seront plus précisément décrits dans la suite de ce cours.
Nous avons relevé trois parties interdépendantes qui relèvent de la construction d'un entrepôt de données :
1. L'étude préalable qui va poser la question du retour sur investissement, définir les objectifs, préciser la démarche.
2. L'étude du modèle des données qui représente l'entrepôt conceptuellement et logiquement.
3. L'étude de l'alimentation qui reprend à un niveau plus précis l'examen des données, le choix des méthodes et des dates auxquelles les données entreront dans l'entrepôt.
Nous terminons par quelques remarques sur les machines dédiées aux entrepôts de données et les optimisations à mettre en oeuvre pour assurer de bons temps de réponse.
1.2.1 Étude préalable
Cette partie de l'étude ressemble à toute étape préliminaire à l'implantation d'un nouveau système d'information automatisé. Les principes des méthodes connues pour le système de production restent valables ici.
Étude des besoins
L'étude des besoins doit déterminer le contenu de l'entrepôt et son organisation, d'après les résultats attendus par les utilisateurs, les requêtes qu'ils formuleront, les projets qui ont été définis. Le besoin d'informatisation peut provenir du système de pilotage ou d'un service particulier de l'entreprise. C'est souvent un projet au sein d'un schéma directeur qui va déclencher l'étude et la réalisation d'un cahier des charges. L'existant dans ce domaine est généralement un ensemble de petits produits ou développements sans grande intégration ni relations, disséminés dans divers services. L'information est dupliquée, les traitements répétés et aucune stratégie d'ensemble n'est définie. Le projet va donc s'orienter vers la recherche d'une solution intégrante résolument tournée vers l'utilisateur.
L'expression des besoins par les utilisateurs met souvent en évidence la volonté d'obtenir : des analyses sur ce qui s'est passé (par exemple comparer les performances actuelles d'un magasin avec celles de l'année dernière) ou des analyses prédictives (par exemple déterminer les achats potentiels pour un type de client, déterminer les clients qui risquent d'abandonner l'entreprise, ...).
Les interviews doivent permettre de préciser les faits à suivre et dans quelles dimensions. Il faut recenser les données nécessaires à un bon fonctionnement de l'entrepôt. Il faut alors recenser les données disponibles dans les bases de production, toutes les données de production ne sont pas utiles dans l'entrepôt. Il faut aussi identifier les données supplémentaires requises et s'assurer la possibilité de se les procurer (achat de bases géographiques, démographiques, ...).
L'examen des dimensions dans lesquelles les faits seront suivis doit donner lieu à une étude de l'unité de ces dimensions, de la granularité de ces faits. Par exemple, l'unité de temps doit-elle être le jour, la semaine ? Les produits sont-ils analysés par catégorie, par lot, par marque ?
La variété des besoins, leur modularité peut entraîner un découpage de l'entrepôt en plusieurs parties : les datamart. Les datamart sont alimentés par un entrepôt et sont dédiés à une activité particulière pour un ou plusieurs services (le suivi des clients, la prévision des stocks). On peut mener l'analyse soit de façon ascendante (en commençant par les datamart), soit de manière descendante.
Le lecteur intéressé est encouragé à consulter les neuf règles pour la conception d'entrepôts de données proposées par Ralf Kimball ([Kim97]).
Coûts de déploiement
Il faut une machine puissante, souvent une machine parallèle, spécialisée pour cette tâche. Les tentatives de mixer à la fois l'informatique de décision et l'informatique de production au sein d'une seule machine sont souvent des échecs. Comme nous l'avons vu précédemment les utilisations sont trop différentes. La capacité de stockage doit être très importante. Les prévisions de montée en charge du système devront évaluer cette quantité. Il faut noter que les prix de ces matériels ne cessent de décroître. En vertu de la loi de Moore, la puissance de stockage (resp. de calcul) est multipliée par deux tous les 2 ans (resp. 18 mois) et cette tendance s'accélère même, à prix constant.
Comme tout système informatique, il faut une équipe pour le maintenir, le faire évoluer (administrateur, développeurs, concepteurs,...). Il faut prévoir la mise en place, la formation, etc.
Les coûts logiciels peuvent être importants. Ils concernent les logiciels d'administration de l'entrepôt, des logiciels d'interrogation et de visualisation ainsi que les coûts de l'environnement logiciel de data mining proprement dit. L'entrepôt devra être accessible par tout utilisateur et on se situe, généralement, dans un environnement client-serveur.
Bénéfices attendus
Nous verrons, au chapitre suivant, qu'il est possible de développer un projet d'extraction de connaissances à partir de données sans mise en place d'un entrepôt de données. Cependant, par définition de l'entrepôt, les données ont été préparées et le travail sera donc facilité.
Il est possible de calculer les espérances de gain en prévoyant les performances du système. Il faut, pour cela, effectuer une étude exhaustive des services de l'entreprise demandeurs d'un environnement d'aide à la décision à partir de données. Pour chacun des services, il faut recenser des projets sur lesquels des bénéfices peuvent être retirés d'une telle implantation. Pour chacun des projets, il faut alors estimer les bénéfices attendus.
Prenons l'exemple du service marketing direct qui veut augmenter le taux de réponse aux courriers qu'elle envoie. À l'aide d'un entrepôt de données, elle va mémoriser son activité et tenter d'établir des profils dans sa clientèle. Si un outil de fouille de données permet de prédire avec un certain taux d'erreur si un client répondra ou non au courrier, la société peut cibler son action. Avec des mailings maintenant ciblés, elle peut réduire le nombre d'envois tout en conservant le même nombre de retours. L'économie peut alors être quantifiée et comparée aux coûts d'investissement.
Il est important de noter que, au vu des investissements nécessaires, il est fréquent de commencer par le développement de serveurs départementaux pour l'entrepôt (Datamart) sur des projets clairement définis avant de passer à une généralisation à l'ensemble des services de l'entreprise.
L'étude préalable se conclue par la rédaction d'un cahier des charges comprenant la solution envisagée, le bilan du retour sur investissement et la décision d'implantation.
1.2 Construction d'un entrepôt
L'entrepôt de données est donc bien différent des bases de données de production car les besoins pour lesquels on veut le construire sont différents. Il contient des informations historisées, globalement cohérentes, organisées selon les métiers de l'entreprise pour le processus de décision. L'entrepôt n'est pas un produit ou un logiciel mais un environnement. Il se bâtit et ne s'achète pas. Les données sont puisées dans les bases de production, nettoyées, normalisées, puis intégrées. Des métadonnées décrivent les informations dans cette nouvelle base pour lever toute ambiguïté quant à leur origine et leur signification.
Nous décrivons, dans ce chapitre, les problèmes liés à la construction d'un entrepôt, les modèles de données et son alimentation. Mais, il faut garder à l'esprit qu'un entrepôt se conçoit avec un ensemble d'applications qui vont réaliser ce pour quoi il a été construit : l'aide à la décision. Ce sont des outils d'accès aux données (requêteurs, visualisateurs, outils de fouille, ...) qui seront plus précisément décrits dans la suite de ce cours.
Nous avons relevé trois parties interdépendantes qui relèvent de la construction d'un entrepôt de données :
1. L'étude préalable qui va poser la question du retour sur investissement, définir les objectifs, préciser la démarche.
2. L'étude du modèle des données qui représente l'entrepôt conceptuellement et logiquement.
3. L'étude de l'alimentation qui reprend à un niveau plus précis l'examen des données, le choix des méthodes et des dates auxquelles les données entreront dans l'entrepôt.
Nous terminons par quelques remarques sur les machines dédiées aux entrepôts de données et les optimisations à mettre en oeuvre pour assurer de bons temps de réponse.
1.2.1 Étude préalable
Cette partie de l'étude ressemble à toute étape préliminaire à l'implantation d'un nouveau système d'information automatisé. Les principes des méthodes connues pour le système de production restent valables ici.
Étude des besoins
L'étude des besoins doit déterminer le contenu de l'entrepôt et son organisation, d'après les résultats attendus par les utilisateurs, les requêtes qu'ils formuleront, les projets qui ont été définis. Le besoin d'informatisation peut provenir du système de pilotage ou d'un service particulier de l'entreprise. C'est souvent un projet au sein d'un schéma directeur qui va déclencher l'étude et la réalisation d'un cahier des charges. L'existant dans ce domaine est généralement un ensemble de petits produits ou développements sans grande intégration ni relations, disséminés dans divers services. L'information est dupliquée, les traitements répétés et aucune stratégie d'ensemble n'est définie. Le projet va donc s'orienter vers la recherche d'une solution intégrante résolument tournée vers l'utilisateur.
L'expression des besoins par les utilisateurs met souvent en évidence la volonté d'obtenir : des analyses sur ce qui s'est passé (par exemple comparer les performances actuelles d'un magasin avec celles de l'année dernière) ou des analyses prédictives (par exemple déterminer les achats potentiels pour un type de client, déterminer les clients qui risquent d'abandonner l'entreprise, ...).
Les interviews doivent permettre de préciser les faits à suivre et dans quelles dimensions. Il faut recenser les données nécessaires à un bon fonctionnement de l'entrepôt. Il faut alors recenser les données disponibles dans les bases de production, toutes les données de production ne sont pas utiles dans l'entrepôt. Il faut aussi identifier les données supplémentaires requises et s'assurer la possibilité de se les procurer (achat de bases géographiques, démographiques, ...).
L'examen des dimensions dans lesquelles les faits seront suivis doit donner lieu à une étude de l'unité de ces dimensions, de la granularité de ces faits. Par exemple, l'unité de temps doit-elle être le jour, la semaine ? Les produits sont-ils analysés par catégorie, par lot, par marque ?
La variété des besoins, leur modularité peut entraîner un découpage de l'entrepôt en plusieurs parties : les datamart. Les datamart sont alimentés par un entrepôt et sont dédiés à une activité particulière pour un ou plusieurs services (le suivi des clients, la prévision des stocks). On peut mener l'analyse soit de façon ascendante (en commençant par les datamart), soit de manière descendante.
Le lecteur intéressé est encouragé à consulter les neuf règles pour la conception d'entrepôts de données proposées par Ralf Kimball ([Kim97]).
Coûts de déploiement
Il faut une machine puissante, souvent une machine parallèle, spécialisée pour cette tâche. Les tentatives de mixer à la fois l'informatique de décision et l'informatique de production au sein d'une seule machine sont souvent des échecs. Comme nous l'avons vu précédemment les utilisations sont trop différentes. La capacité de stockage doit être très importante. Les prévisions de montée en charge du système devront évaluer cette quantité. Il faut noter que les prix de ces matériels ne cessent de décroître. En vertu de la loi de Moore, la puissance de stockage (resp. de calcul) est multipliée par deux tous les 2 ans (resp. 18 mois) et cette tendance s'accélère même, à prix constant.
Comme tout système informatique, il faut une équipe pour le maintenir, le faire évoluer (administrateur, développeurs, concepteurs,...). Il faut prévoir la mise en place, la formation, etc.
Les coûts logiciels peuvent être importants. Ils concernent les logiciels d'administration de l'entrepôt, des logiciels d'interrogation et de visualisation ainsi que les coûts de l'environnement logiciel de data mining proprement dit. L'entrepôt devra être accessible par tout utilisateur et on se situe, généralement, dans un environnement client-serveur.
Bénéfices attendus
Nous verrons, au chapitre suivant, qu'il est possible de développer un projet d'extraction de connaissances à partir de données sans mise en place d'un entrepôt de données. Cependant, par définition de l'entrepôt, les données ont été préparées et le travail sera donc facilité.
Il est possible de calculer les espérances de gain en prévoyant les performances du système. Il faut, pour cela, effectuer une étude exhaustive des services de l'entreprise demandeurs d'un environnement d'aide à la décision à partir de données. Pour chacun des services, il faut recenser des projets sur lesquels des bénéfices peuvent être retirés d'une telle implantation. Pour chacun des projets, il faut alors estimer les bénéfices attendus.
Prenons l'exemple du service marketing direct qui veut augmenter le taux de réponse aux courriers qu'elle envoie. À l'aide d'un entrepôt de données, elle va mémoriser son activité et tenter d'établir des profils dans sa clientèle. Si un outil de fouille de données permet de prédire avec un certain taux d'erreur si un client répondra ou non au courrier, la société peut cibler son action. Avec des mailings maintenant ciblés, elle peut réduire le nombre d'envois tout en conservant le même nombre de retours. L'économie peut alors être quantifiée et comparée aux coûts d'investissement.
Il est important de noter que, au vu des investissements nécessaires, il est fréquent de commencer par le développement de serveurs départementaux pour l'entrepôt (Datamart) sur des projets clairement définis avant de passer à une généralisation à l'ensemble des services de l'entreprise.
L'étude préalable se conclue par la rédaction d'un cahier des charges comprenant la solution envisagée, le bilan du retour sur investissement et la décision d'implantation.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Mar 21 Juil - 16:58
1.2.2 Modèles de données
Niveau conceptuel
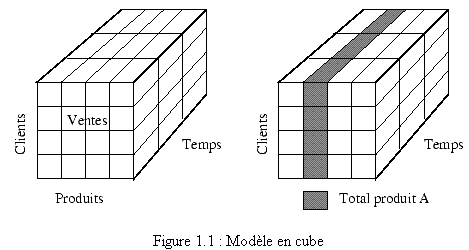
Le modèle conceptuel doit être simplifié au maximum pour permettre au plus grand nombre d'appréhender l'organisation des données, comprendre ce que l'entrepôt mémorise. On parle de modèle multidimensionnel, souvent représenté sous forme de cube, parce que les données seront toujours des faits à analyser suivant plusieurs dimensions. Par exemple, dans le cas de ventes de produits à des clients dans le temps (3 dimensions, un vrai cube), les faits sont les ventes, les dimensions sont les clients, les produits et le temps. Les interrogations s'interprètent souvent comme l'extraction d'un plan, d'une droite de ce cube (e.g. lister les ventes du produit A ou lister les ventes du produit A sur période de temps D), ou l'agrégation de données le long d'un plan ou d'une droite (e.g. Obtenir le total des ventes du produit A revient à sommer les éléments du plan indiqué en figure 1.1).
Un avantage évident de ce modèle est sa simplicité, dès que les mots ventes, clients, produits et temps sont précisés, désambiguisés. Il reprend les termes et la vision de l'entreprise de tout utilisateur final concerné par les processus de décision. Même si dans un entrepôt important il peut exister plusieurs cubes, parce qu'il est nécessaire de suivre plusieurs faits dans des directions parfois identiques, parfois différentes, l'utilisateur pourra accéder à des versions simplifiées, car plus ciblées, dans des datamarts.
Niveau logique
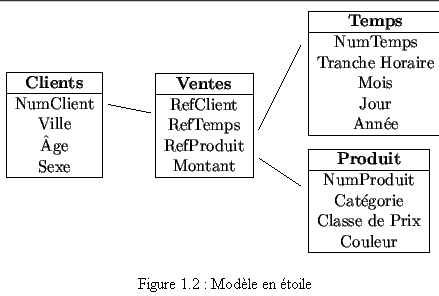
Au niveau logique, l'unité de base est la table comme dans le modèle relationnel. L'implantation classique consiste à considérer un modèle en étoile avec au centre la table des faits et les dimensions comme autant de branches à l'étoile. Les branches de l'étoile sont des relations de 1 à plusieurs, la table des faits est énorme contrairement aux tables des dimensions. Le modèle est en cela très dissymétrique en comparaison avec les modèles relationnels des bases de production. Encore une fois, la simplicité du modèle obtenu rend la construction en étoile très attrayante.
Les faits sont qualifiés par des champs qui sont le plus souvent numériques et cumulatifs comme des prix, des quantités et des clés évidemment pour relier les faits à chaque dimension. Les tables des dimensions sont caractérisées par des champs le plus souvent textuels. Dans l'exemple présenté en figure 1.2, nous nous limitons au suivi d'un seul fait : le montant des ventes. Un enregistrement dans la table des faits Ventes correspond à un total des ventes à un client dans une tranche horaire d'un jour précis, pour un produit choisi.
Il existe un modèle concurrent : le modèle en flocon. L'avantage mis en avant par les tenants de ce modèle est l'économie de place de stockage. Mais, le plus souvent, un examen approfondi montre que cette structure n'apporte rien, et complique même le modèle. Quand une hiérarchie apparaît dans une dimension, il est préférable de tout enregistrer dans une seule et même table formant une grande dimension. Par exemple, pour une dimension produit avec des catégories, puis des sous-catégories (et ainsi de suite), toutes les échelles sont conservées dans la même table de dimension. Il sera ensuite possible de naviguer (ou forer) par des opérations de zoom dans cette échelle (en anglais drill up et drill down).
Niveau conceptuel
Le modèle conceptuel doit être simplifié au maximum pour permettre au plus grand nombre d'appréhender l'organisation des données, comprendre ce que l'entrepôt mémorise. On parle de modèle multidimensionnel, souvent représenté sous forme de cube, parce que les données seront toujours des faits à analyser suivant plusieurs dimensions. Par exemple, dans le cas de ventes de produits à des clients dans le temps (3 dimensions, un vrai cube), les faits sont les ventes, les dimensions sont les clients, les produits et le temps. Les interrogations s'interprètent souvent comme l'extraction d'un plan, d'une droite de ce cube (e.g. lister les ventes du produit A ou lister les ventes du produit A sur période de temps D), ou l'agrégation de données le long d'un plan ou d'une droite (e.g. Obtenir le total des ventes du produit A revient à sommer les éléments du plan indiqué en figure 1.1).
Un avantage évident de ce modèle est sa simplicité, dès que les mots ventes, clients, produits et temps sont précisés, désambiguisés. Il reprend les termes et la vision de l'entreprise de tout utilisateur final concerné par les processus de décision. Même si dans un entrepôt important il peut exister plusieurs cubes, parce qu'il est nécessaire de suivre plusieurs faits dans des directions parfois identiques, parfois différentes, l'utilisateur pourra accéder à des versions simplifiées, car plus ciblées, dans des datamarts.
Niveau logique
Au niveau logique, l'unité de base est la table comme dans le modèle relationnel. L'implantation classique consiste à considérer un modèle en étoile avec au centre la table des faits et les dimensions comme autant de branches à l'étoile. Les branches de l'étoile sont des relations de 1 à plusieurs, la table des faits est énorme contrairement aux tables des dimensions. Le modèle est en cela très dissymétrique en comparaison avec les modèles relationnels des bases de production. Encore une fois, la simplicité du modèle obtenu rend la construction en étoile très attrayante.
Les faits sont qualifiés par des champs qui sont le plus souvent numériques et cumulatifs comme des prix, des quantités et des clés évidemment pour relier les faits à chaque dimension. Les tables des dimensions sont caractérisées par des champs le plus souvent textuels. Dans l'exemple présenté en figure 1.2, nous nous limitons au suivi d'un seul fait : le montant des ventes. Un enregistrement dans la table des faits Ventes correspond à un total des ventes à un client dans une tranche horaire d'un jour précis, pour un produit choisi.
Il existe un modèle concurrent : le modèle en flocon. L'avantage mis en avant par les tenants de ce modèle est l'économie de place de stockage. Mais, le plus souvent, un examen approfondi montre que cette structure n'apporte rien, et complique même le modèle. Quand une hiérarchie apparaît dans une dimension, il est préférable de tout enregistrer dans une seule et même table formant une grande dimension. Par exemple, pour une dimension produit avec des catégories, puis des sous-catégories (et ainsi de suite), toutes les échelles sont conservées dans la même table de dimension. Il sera ensuite possible de naviguer (ou forer) par des opérations de zoom dans cette échelle (en anglais drill up et drill down).
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Mar 21 Juil - 17:01
Avant de continuer reliez encore une autre fois, et essayer de bien comprendre touts les notions citées, et si vous n'arrivez pas a comprendre une chose faite le moi savoir.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Découverte de connaissance a partir des données
par fatehdz Lun 27 Juil - 15:45
La suite est sur:
http://statisticien-dz.forums-actifs.net/datamining-f34/dycouverte-de-connaissance-a-partir-des-donnyes-t40.htm#133
http://statisticien-dz.forums-actifs.net/datamining-f34/dycouverte-de-connaissance-a-partir-des-donnyes-t40.htm#133
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Page 1 sur 1
Permission de ce forum:
Vous ne pouvez pas répondre aux sujets dans ce forum|
|
|