
Aucun
Le record du nombre d'utilisateurs en ligne est de 53 le Jeu 15 Aoû - 21:39
| Cendrillon | ||||
| dragoun | ||||
| moh748 | ||||
| ThE RiadH | ||||
| necropathologist7 | ||||
| onlystyle | ||||
| Carlo | ||||
| nanoussa | ||||
| desmond | ||||
| Imperial Phoenix |



L'utilisateur enregistré le plus récent est gusgus
Nos membres ont posté un total de 22812 messages dans 1131 sujets


Apprendre "R" un logiciel statistique gratuit

Apprendre "R" un logiciel statistique gratuit
par fatehdz Ven 27 Mar - 18:32
Je vais vous parler aujourd'hui d'un logiciel statistique très puissant qui s'appelle R.
et pour ça je vais reprendre l'introduction d'Emmanuel Paradis auteur de la doc "R pour les débutants"
R est un système d'analyse statistique et graphique créee par Ross Ihaka et Robert Gentleman1. R est à la fois un logiciel et un langage quali fié de dialecte du langage S crée par AT&T Bell Laboratories. S est disponible sous la forme du logiciel S-PLUS commercialisée par la compagnie Insightful2. Il y a des déférences importantes dans la conception de R et celle de S : ceux qui veulent en savoir plus sur ce point peuvent se reporter à l'article de Ihaka & Gentleman (1996) ou au R-FAQ3 dont une copie est également distribuée avec R.
R est distribué librement sous les termes de la GNU General Public Licence4; son développement et sa distribution sont assurés par plusieurs statisticiens rassemblés dans le R Development Core Team.
R est disponible sous plusieurs formes : le code (écrit principalement en C et certaines routines en Fortran), surtout pour les machines Unix et Linux, ou des exécutables précompilés pour Windows, Linux et Macintosh. Les fichiers pour installer R, à partir du code ou des exécutables, sont distribués à partir du site internet du Comprehensive R Archive Network (CRAN)5 où se trouvent aussi les instructions à suivre pour l'installation sur chaque système. En ce qui concerne les distributions de Linux (Debian, . . .), les exécutables sont généralement disponibles pour les versions les plus récentes ; consultez le site du CRAN si besoin.
R comporte de nombreuses fonctions pour les analyses statistiques et les graphiques ; ceux-ci sont visualisés immédiatement dans une fenétre propre et peuvent être exportés sous divers formats (jpg, png, bmp, ps, pdf, emf, pictex, ; les formats disponibles peuvent dépendre du système d'exploitation).
Les résultats des analyses statistiques sont affichés à l'écran, certains résultats partiels (valeurs de P, coéficients de régression, résidus, . . .) peuvent être sauvés à part, exportés dans un chier ou utilisés dans des analyses ultérieures.
Le langage R permet, par exemple, de programmer des boucles qui vont analyser successivement différents jeux de données. Il est aussi possible de combiner dans le même programme différentes fonctions statistiques pour réaliser des analyses plus complexes. Les utilisateurs de R peuvent bénéficier des nombreux programmes écrits pour S et disponibles sur internet, la plupart de ces programmes étant directement utilisables avec R.
De prime abord, R peut sembler trop complexe pour une utilisation par un non-spécialiste. Ce n'est pas forcément le cas. En fait, R privilégie la flexibilité. Alors qu'un logiciel classique affichera directement les résultats d'une analyse, avec R ces résultats sont stockés dans un "objet", si bien qu'une analyse peut être faite sans qu'aucun résultat ne soit affiché. L'utilisateur peut
être déconcerté par ceci, mais cette facilité se révèle extrêmement utile.
En effet, l'utilisateur peut alors extraire uniquement la partie des résultats qui
l'intéresse. Par exemple, si l'on doit faire une série de 20 régressions et que
l'on veuille comparer les coefficients des différentes régressions, R pourra afficher uniquement les coefficients estimés : les résultats tiendront donc sur une ligne, alors qu'un logiciel plus classique pourra ouvrir 20 fenêtres de résultats. On verra d'autres exemples illustrant la flexibilité d'un système comme R vis-à-vis des logiciels classiques.
Comment R travaille ? (Denis Poinsot)
R utilise un langage informatique dit orienté objet. Ne partez pas ! Vous n'avez rien à programmer, mais vous pourrez vous délecter des aspects pratiques qui en découlent. Pour faire simple, un objet est une sorte de fichier. Il peut contenir par exemple des données, ou bien le résultat de tests que vous avez demandés. La très grande supériorité d'un objet sur un fichier est la suivante. Les seules opérations que vous puissiez effectuer sur un fichier sont :
ouvrir/fermer et copier/déplacer/effacer. Pour agir sur le contenu d'un fichier, il faut d'abord l'ouvrir. Combiner le contenu de fichiers différents par exemple demande des opérations fastidieuses à base de couper/coller. Pas dans R. En effet, tout objet possède une structure interne formée d'objets plus petits sur lesquels vous pouvez agir séparément, mais aussi globalement. Pour l'instant, ça ne vous dit rien mais vous verrez que c'est d'une efficacité redoutable. Voyons simplement comment on entre des données dans un objet.
La manière la plus primaire est de saisir les données directement dans R. Rassurez-vous, la manière de récupérer les données de vos tableaux Excel (ou autre) vous est présentée aussi, en Annexe 1. Supposons pour l'instant que nous voulions étudier la taille moyenne d'étudiants de sexe masculin et féminins en vous basant sur deux échantillons aléatoires de 10 et 8 personnes respectivement. La saisie des données est alors :
> men = c(172.5, 175, 176, 177, 177, 178.5, 179, 179, 179.5, 180)
> women = c(167, 168, 168.5, 170, 171, 175, 175, 176)
Notez bien les points suivants :
1) on peu nommer les objets librement, donc autant le faire de manière explicite. Le choix de l’anglais évite d’utiliser les lettres accentuées (é, à, ç...) que R n’aimera pas trop si vous utilisez une version anglaise du logiciel, origine anglo-saxonne oblige. Un conseil : dans R, nommez donc vos variables avec des noms anglais, ça vous évitera d’ajouter inconsciemment des accents partout.
2) pour former une liste de données qui sera ensuite manipulée éventuellement d'un bloc, il suffit de lui donner un nom, de faire suivre ce nom du signe "=" puis de lister les valeurs séparées par des virgules, le tout entre parenthèses ( ) et précédé de la lettre c (qui est l'abréviation de concatenate c'est à dire "faire une chaîne avec les éléments")
3) du fait que la virgule sert de séparateur entre les valeurs, le séparateur décimal dans R est le point décimal anglo-saxon et non la virgule.
R sait maintenant que les noms men et women désignent deux objets bien précis, et il est capable de les manipuler globalement comme d’effectuer des opérations sur eux. Il peut évidemment lister leur contenu, il suffit de les appeler par leur nom (peut on imaginer plus simple ?) :
> men
Réponse :
[1] 172.5
[2] 175
[3] 176
[4] 177
[5] 177
[6] 178.5
[7] 179
[8] 179
[9] 179.5
[10] 180
Vous remarquerez que le listing est numéroté, et vous indique le rang de chaque valeur dans le tableau initial. Pour connaître respectivement la moyenne, la variance, l'écart-type ou tout simplement pour vérifier l'effectif de votre échantillon, les instructions sont les suivantes (en rouge les réponses de R):
> mean(men)
[1] 177.35
Donner la moyenne de l'objet men
> var(men)
[1] 5.502778 Donner la variance de l'objet men
> sd(men)
[1] 2.3458 Donner l'écart-type (sd=standard deviation) de l'objet men
Supposons maintenant que nous voulions faire un test t de Student entre ces deux moyennes.
Avec un logiciel classique, il nous faudrait cliquer sur un menu déroulant "tests
paramétriques" puis "test de comparaison de moyennes" puis , puis "test t de Student", etc et une dizaine de clics plus tard vous auriez enfin eu ce que vous vouliez. Maintenant comparez avec ceci :
>t.test(men,women)
Alors, c'est compliqué R ? Nous découvrirons la réponse de R à cette demande de test de Student dans la section 4.1 consacrée au test de Student. Voyons pour l'instant quelques autres fonctions de base très utiles.
......................................................
Bon, voila c'été un avant gout des possibilités offerte par R, Je développerais plus le sujet plus tard.
En attendant vous pouvez télécharger R sur http://www.r-project.org/
et pour la doc un tres bon site : http://pbil.univ-lyon1.fr/R/enseignement.html
Dernière édition par fatehdz le Dim 29 Mar - 14:36, édité 1 fois

fatehdz- Bavard

-

Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Sam 28 Mar - 1:42
merci encore une fois

samsamo- Bavard
-

Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Dim 29 Mar - 15:28
J'ai décidé de vous faire par de quelques fonctionnalité de R l'histoire d'apprendre un peu à l'utiliser. Mais peut être que quelqu'un d'entre vous me dis pourquoi apprendre à maitriser R alors qu'il y a d autres logiciels statistiques plus agréable à manipuler, pourquoi en faite ce compliqué l'existence avec des commandes et de la programmation, et bien la réponse à ces questions est dans ces points suivants :
- R te permet de maitriser tes analyses statistiques en affichant que les résultats qu'en veut voir contrairement aux autres logiciels statistiques qui vous noient avec une dizaines de sorties d'écran et de résultats que tu n'as même pas demandé.
- R te permet de faire des Bootstrap. Tu a dis quoi Bootstrap mais je ne sais même pas ce que c'est ?!
un peu de recherche sur google et tu comprendras surement et pour faire plus vite http://www.iumsp.ch/Unites/us/Alfio/polybiostat/ch16.pdf.
- R te permet de programmer toute une analyse statistique de A-Z, et d'en afficher que les résultats pertinents.
- R dispose d'une très grande communauté de chercheurs de praticiens et de professeurs à travers le monde, il à une communauté très active, et un forum ou tu peut trouvé toutes les réponses à tes questions.
- R et pour la statistique ce que L'unix et pour l'informatique, il est considéré comme le logiciel open source concurrent numéro un du très puissant logiciel commerciale SAS, car il possède des fonctionnalité très très puissante dans le domaine du data mining, et de l'analyse exploratoire multidimensionnelle.
- R n'est pas aussi difficile à apprendre qu'il en a l'air.
- Et le point le plus important et que R est gratuit, l'Algérie est entrain de signer des conventions internationale sur la protection des droits d'utilisations des logiciels commerciale, ce qui veut dire que d'ici quelques années toutes les entreprises devront suivrent la réglementation en terme de licences d'utilisation des logiciels commerciaux, connaissant les couts que ça engendre, je ne suis pas sur que les entreprise vont acheter des licences pour les logiciels statistiques tel que SPSS, Statistica, et encore loin SAS qui sont très chère. Donc il faut qu'on anticipe tous ça en commençant dès aujourd'hui à apprendre les logiciel open source gratuit tel que R, ce qui nous permettra de sortir de ce problème des licences d'utilisation, plusieurs sociétés notamment en France et au usa en commencé à utiliser R comme étant leur système d'analyse statistique après que ce dernier a prouvé son efficacité dans les milieu de la recherche académique.
Pour toute ces raisons et pour d'autres R est devenu un logiciel incontournable pour tout statisticien digne de ce nom.
et c'est pour ça que j'ai décider d'apprendre ce logiciel et j'aimerais que vous me rejoignez dans cette phase apprentissage afin de s'entre aider ensemble et pourquoi pas créer un petite communauté algérienne de R.
Donc, je vais poster une introduction rapide au fonctionnalités les plus courantes de R (statistique descriptive), puis j'attaquerais les méthodes de statistiques exploratoires multidimensionnelle (ACP, AFC, AFD, AFCM...) et quelques techniques du Data Mining vu que je suis entrain de suivre une série de conférence vidéos sur l'application des techniques de data mining à l'aide du logiciel R donner par un professeur de stanford(pour ceux qui sont intéressés je peut vous donner les liens pour visionner les conférences et télécharger les données pour l'application pratique).
Comme , vous l'avez vu je vais me focaliser sur les techniques de statistiques appliquée vu que c'est ma spécialité, et j'aimerais que ceux de la spécialité finance participe en montrant comment appliquer les techniques de calculs financières et actuarielles vu que R possède pas mal de fonctionnalités aussi dans ce domaine.
Voila, j'aimerais que vous seriez nombreux à participer dans cette initiative, afin d'aller loin dans ce projet, et j'en suis sur que après quelques exemples d'application vous allez devenir accros, car vous allez enfin comprendre à quoi sert toute cette théorie avec qui on vous bourre la tête du matin au soir.
Voila n'hésitez pas à m'encourager et vous encourager pour qu'on arrive enfin dans ce forum à faire quelques choses de constructive.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Dim 29 Mar - 18:12
Après avoir installer le logiciel R (Télécharger le à partir du site :http://www.r-project.org/ et choisissez votre OS: Windows)vous obtenez une fenêtre appelée console. Celle-ci contient un petit texte de bienvenue
ressemblant à peu près à ce qui suit
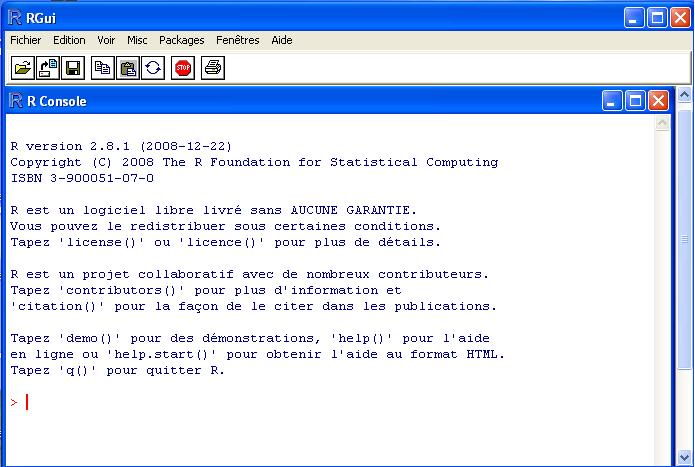
le caractère > et sur laquelle devrait se trouver votre curseur. Cette ligne est appelée l’invite de commande (ou prompt en anglais). Elle signifie que R est disponible et en attente de votre prochaine commande.
Nous allons tout de suite lui fournir une première commande :
R> 2 + 3
La réponse de R ne se fait pas attendre :
[1] 5
Bien, nous savons désormais que R sait faire les additions à un chiffre 2. Nous pouvons désormais continuer avec d’autres opérations arithmétiques de base :
R> 8 - 12
[1] -4
R> 14 * 25
[1] 350
R> -3/10
[1] -0.3
Astuce: Une petite astuce très utile lorsque vous tapez des commandes directement dans la console : en utilisant les flèches Haut et Bas du clavier, vous pouvez naviguer dans l’historique des commandes tapées précédemment, que vous pouvez alors facilement réexécuter ou modifier.
Lorsqu’on fournit à R une commande incomplète, celui-ci nous propose de la compléter en nous présentant une invite de commande spéciale utilisant les signe +. Imaginons par exemple que nous avons malencontreusement tapé sur Entrée alors que nous souhaitions calculer 4*3 :
R> 4 *
+
On peut alors compléter la commande en saisissant simplement 3 :
R> 4 *
+ 3
[1] 12
Astuce : Pour des commandes plus complexes, il arrive parfois qu’on se retrouve coincé avec un invite + sans plus savoir comment compléter la saisie correctement. On peut alors annuler la commande en utilisant la touche Echap ou Esc sous Windows. Sous Linunx on utilise le traditionnel Control + C.
À noter que les espaces autour des opérateurs n’ont pas d’importance lorsque l’on saisit les commandes dans R. Les trois commandes suivantes sont donc équivalentes, mais on privilégie en général la deuxième pour des raisons de lisibilité du code.
R> 10+2
R> 10 + 2
R> 10 + 2
Les Objets :
- Objets Simples :
Faire des opérations arithmétiques, c’est bien, mais sans doute pas totalement suffisant. Notamment,on aimerait pouvoir réutiliser le résultat d’une opération sans avoir à le resaisir ou à le copier/coller.
Comme tout langage de programmation, R permet de faire cela en utilisant des objets. Prenons tout de suite un exemple :
R> x <- 2
R> x
[1] 2
Que signifie cette commande ? L’opérateur <- est appelé opérateur d’assignation. Il prend une valeur quelconque à droite et la place dans l’objet indiqué à gauche. La commande pourrait donc se lire mettre la valeur 2 dans l’objet nommé x.
On va ensuite pouvoir réutiliser cet objet dans d’autres calculs ou simplement afficher son contenu :
R> x + 3
[1] 5
On peut utiliser autant d’objets qu’on veut. Ceux-ci peuvent contenir des nombres, des chaînes de caractères (indiquées par des guillemets droits ") et bien d’autres choses encore :
R> x <- 27
R> y <- 10
R> foo <- x + y
R> foo
[1] 37
C'est tellement simple n'est ce pas ? Continuons alors
R> x <- "Hello"
R> foo <- x
R> foo
[1] "Hello"
Remarque : Les noms d’objets peuvent contenir des lettres, des chiffres (mais ils ne peuvent pas commencer par un chiffre) et les symboles . et _. R fait la différence entre les majuscules et les minuscules, ce qui signifie que x et X sont deux objets différents. Enfin, on évitera d’utiliser des caractères accentués dans les noms d’objets, et comme les espaces ne sont pas autorisés on pourra les remplacer par un point ou un tiret bas.
Vecteurs :
Imaginons maintenant que nous avons interrogé dix personnes au hasard dans la rue et que nous avons relevé pour chacune d’elle sa taille en centimètres. Nous avons donc une série de dix nombres que nous souhaiterions pouvoir réunir de manière à pouvoir travailler sur l’ensemble de nos mesures.
Un ensemble de données de même nature constituent pour R un vecteur (en anglais vector) et se construit à l’aide d’un opérateur nommé c (c'est l’abbréviation de combine ou concatenate en anglais. Le nom de cette fonction est très court car on l’utilise très souvent..) On l’utilise en lui donnant la liste de nos données, entre parenthèses, séparées par des virgules :
R> tailles <- c(167, 192, 173, 174, 172, 167, 171, 185, 163,
+ 170)
Ce faisant, nous avons créé un objet nommé tailles et comprenant l’ensemble de nos données, que nous pouvons afficher :
R> tailles
[1] 167 192 173 174 172 167 171 185 163 170
Dans le cas où notre vecteur serait beaucoup plus grand, et comporterait par exemple 40 tailles, on aurait le résultat suivant :
R> tailles
[1] 144 168 179 175 182 188 167 152 163 145 176 155 156 164 167 155 157
[18] 185 155 169 124 178 182 195 151 185 159 156 184 172 156 160 183 148
[35] 182 126 177 159 143 161 180 169 159 185 160
On a bien notre suite de quarante tailles, mais on peut remarquer la présence de nombres entre crochets au début de chaque ligne ([1], [18] et [35]). En fait ces nombres entre crochets indiquent la position du premier élément de la ligne dans notre vecteur. Ainsi, le 185 en début de deuxième ligne est le 18ème élément du vecteur, tandis que le 182 de la troisième ligne est à la 35ème position.
On en déduira d’ailleurs que lorsque l’on fait :
R> 2
[1] 2
R considère en fait le nombre 2 comme un vecteur à un seul élément.
On peut appliquer des opérations arithmétiques simples directement sur des vecteurs :
R> tailles <- c(167, 192, 173, 174, 172, 167, 171, 185, 163,
+ 170)
R> tailles + 20
[1] 187 212 193 194 192 187 191 205 183 190
R> tailles/100
[1] 1.67 1.92 1.73 1.74 1.72 1.67 1.71 1.85 1.63 1.70
R> tailles^2
[1] 27889 36864 29929 30276 29584 27889 29241 34225 26569 28900
On peut aussi combiner des vecteurs entre eux. L’exemple suivant calcule l’indice de masse corporelle
à partir de la taille et du poids :
R> tailles <- c(167, 192, 173, 174, 172, 167, 171, 185, 163,
+ 170)
R> poids <- c(86, 74, 83, 50, 78, 66, 66, 51, 50, 55)
R> tailles.m <- tailles/100
R> imc <- poids/(tailles.m^2)
R> imc
[1] 30.83653 20.07378 27.73230 16.51473 26.36560 23.66524 22.57105
[8] 14.90139 18.81892 19.03114
Attention: Quand on fait des opérations sur les vecteurs, il faut veiller à soit utiliser un vecteur et un chiffre (dans des opérations du type v * 2 ou v + 10), soit à utiliser des vecteurs de même longueur (dans des opérations
du type u + v).
Si on utilise des vecteurs de longueur différentes, on peut avoir quelques surprises 4.
En effet Quand R effectue une opération avec deux vecteurs de longueurs différentes, il recopie le vecteur le plus court de manière à lui donner la même taille que le plus long, ce qui s’appelle la règle de recyclage (recycling rule). Ainsi, c(1,2) + c(4,5,6,7,
On a vu jusque-là des vecteurs composés de nombres, mais on peut tout à fait créer des vecteurs composés de chaînes de caractères, représentant par exemple les réponses à une question ouverte ou fermée :
R> rep <- c("Bac+2", "Bac", "CAP", "Bac", "Bac", "CAP", "BEP")
Enfin, notons que l’on peut accéder à un élément particulier du vecteur en faisant suivre le nom du vecteur de crochets contenant le numéro de l’élément désiré. Par exemple :
R> rep <- c("Bac+2", "Bac", "CAP", "Bac", "Bac", "CAP", "BEP")
R> rep[2]
[1] "Bac"
Cette opération s’appelle l’indexation d’un vecteur. Il s’agit ici de sa forme la plus simple, mais il en existe d’autres beaucoup plus complexes. L’indexation des vecteurs et des tableaux dans R est l’un des éléments particulièrement souples et puissants du langage (mais aussi l’un des plus délicats à comprendre et à maîtriser). Nous en reparlerons dans les prochaines sections.
Des fonctions :
Nous savons désormais faire des opérations simples sur des nombres et des vecteurs, stocker ces données et résultats dans des objets pour les réutiliser par la suite.
Pour aller un peu plus loin nous allons aborder, après les objets, l’autre concept de base de R, à savoir les fonctions. Une fonction se caractérise de la manière suivante :
– elle a un nom ;
– elle accepte des arguments (qui peuvent avoir un nom ou pas) ;
– elle retourne un résultat et peut effectuer une action comme dessiner un graphique, lire un fichier, etc. ;
En fait rien de bien nouveau puisque nous avons déjà utilisé plusieurs fonctions jusqu’ici, dont la plus visible est la fonction c. Dans la ligne suivante :
R> rep <- c("Bac+2", "Bac", "CAP", "Bac", "Bac", "CAP", "BEP")
on fait appel à la fonction nommée c, on lui passe en arguments (entre parenthèses et séparées par des virgules) une série de chaînes de caractères, et elle retourne comme résultat un vecteur de chaînes de caractères, que nous stockons dans l’objet tailles.
Prenons tout de suite d’autres exemples de fonctions courantes :
R> tailles <- c(167, 192, 173, 174, 172, 167, 171, 185, 163,
+ 170)
R> length(tailles)
[1] 10
R> mean(tailles)
[1] 173.4
R> var(tailles)
[1] 76.71111
Ici, la fonction length nous renvoit le nombre d’éléments du vecteur, la fonction mean nous donne la moyenne des éléments du vecteur, et la fonction var sa variance.
Arguments :
Les arguments de la fonction lui sont indiqués entre parenthèses, juste après son nom. En général les premiers arguments passés à la fonction sont des données servant au calcul, et les suivants des paramètres influant sur ce calcul. Ceux-ci sont en général transmis sous la forme d’argument nommés.
Reprenons l’exemple des tailles précédent :
R> tailles <- c(167, 192, 173, 174, 172, 167, 171, 185, 163,
+ 170)
Imaginons que le deuxième enquêté n’ait pas voulu nous répondre. Nous avons alors dans notre vecteur une valeur manquante. Celle-ci est symbolisée dans R par le code NA :
R> tailles <- c(167, NA, 173, 174, 172, 167, 171, 185, 163,
+ 170)
Recalculons notre taille moyenne :
R> mean(tailles)
[1] NA
Et oui, par défaut, R renvoit NA pour un grand nombre de calculs (dont la moyenne) lorsque les données comportent une valeur manquante. On peut cependant modifier ce comportement en fournissant un paramètre supplémentaire à la fonction mean, nommé na.rm :
R> mean(tailles, na.rm = TRUE)
[1] 171.3333
Positionner le paramètre na.rm à TRUE (vrai) indique à la fonction mean de ne pas tenir compte des valeurs manquantes dans le calcul.
Lorsqu’on passe un argument à une fonction de cette manière, c’est-à-dire sous la forme nom=valeur, on parle d’argument nommé.
Quelques fonctions utiles :
Récapitulons la liste des fonctions que nous avons déjà rencontrées :
Fonction Description
c construit un vecteur à partir d’une série de valeurs
length nombre d’éléments d’un vecteur
mean moyenne d’un vecteur de type numérique
var variance d’un vecteur de type numérique
+, -, *, / opérateurs mathématiques de base
ˆ passage à la puissance
On peut rajouter les fonctions de base suivantes :
Fonction Description
min valeur minimale d’un vecteur numérique
max valeur maximale d’un vecteur numérique
sd écart-type d’un vecteur numérique
: génère une séquence de nombres. 1:4 équivaut à c(1,2,3,4)
Aide sur une fonction
Il est très fréquent de ne plus se rappeler quels sont les paramètres d’une fonction ou le type de résultat qu’elle retourne. Dans ce cas on peut très facilement accéder à l’aide décrivant une fonction particulière en tapant (remplacer fonction par le nom de la fonction) :
R> help("fonction")
Ou, de manière équivalente, ?fonction.
Ces deux commandes affichent une page (en anglais) décrivant la fonction, ses paramètres, son résultat, le tout accompagné de diverses notes, références et exemples. Ces pages d’aide contiennent à peu près tout ce que vous pourrez chercher à savoir, mais elles ne sont pas toujours d’une lecture aisée.
Un autre cas très courant dans R et de ne pas se souvenir ou de ne pas connaître le nom de la fonction effectuant une tâche donnée. Dans ce cas on utiliseras d'autres méthodes pour trouver de l’aide qui seronts décrites plus tard.
Exercices :
Rien de mieux que de vous donnez quelques exercices simple l'histoire de voir si vous avez bien assimiler les concepts étudié plus haut
Exercice 1
Construire le vecteur suivant :
[1] 120 134 256 12
Exercice 2
Générez les vecteurs suivants chacun de deux manières différentes :
[1] 1 2 3 4
[1] 1 2 3 4 8 9 10 11
[1] 2 4 6 8
Exercice 3
On a demandé à 4 ménages le revenu du chef de ménage, celui de son conjoint, et le nombre de personnes du ménage :
R> chef <- c(1200, 1180, 1750, 2100)
R> conjoint <- c(1450, 1870, 1690, 0)
R> nb.personnes <- c(4, 2, 3, 2)
Calculez le revenu total par personne du ménage.
Exercice 4
Dans l’exercice précédent, calculez le revenu minimum et le revenu maximum parmi ceux du chef de ménage :
R> chef <- c(1200, 1180, 1750, 2100)
Recommencer avec les revenus suivants, parmi lesquels l’un des enquêtés n’a pas voulu répondre :
R> chef.na <- c(1200, 1180, 1750, NA)
Merci de poster les reponses des exercices directement dans le sujet et non par MP.
Je donnerais les réponses des exercices après que vous ayez poster vos réponses. Et je reprend la suite des cours.
Bonne chance
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Lun 30 Mar - 2:03
fateh please j'ai remarqué que tu commence tjr par R> est-il nécessaire sachant qu'au logiciel sa débute juste par > et on ajoutant R> sa affiche :Erreur : objet "R" non trouvé
merci d'expliqué
résolution des exo:
exo1
>c(120 ,134, 256, 12)
exo2:
1ier vecteur
>sam<-c(1,2,3,4)
>sam
>1:4
2 ièm vecteur
>c(sam,8:11)
>c(1:4,8:11)
3ème vecteur
>c(sam+sam)
>c(2,4,6,
exo 4:
> chef <- c(1200, 1180, 1750, 2100)
>min(chef)
>max(chef)
> chef.na <- c(1200, 1180, 1750, NA)
>min(chef.na,na.rm=TRUE)
>max(chef.na,na.rm=TRUE)
merci
samsamo- Bavard
-
Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Lun 30 Mar - 20:36
fateh please j'ai remarqué que tu commence tjr par R> est-il nécessaire sachant qu'au logiciel sa débute juste par > et on ajoutant R> sa affiche :Erreur : objet "R" non trouvé
merci d'expliqué
c'été juste pour simuler l'invite te commande, mais si ça prête a confusion, je donnerais directement les fonctions les prochaines fois.
Bienrésolution des exo:
exo1
>c(120 ,134, 256, 12)
c'est bien aussi sauf que tu n'avais pas vraiment besoin d'assigner le vecteur à une variable "sam" mais comme tu as utiliser cette variable dans les prochaines exo c'été une bonne idée.exo2:
1ier vecteur
>sam<-c(1,2,3,4)
>sam
>1:4
très bien c'ette idée de la var sam qui se balade un peu partout.2 ièm vecteur
>c(sam,8:11)
>c(1:4,8:11)
est encore une fois le sam qui aime bien ce montrer, mais pour l'info on peut faire ça aussi >1:4 * 2, et oui avec R on est tellement libre de créer nos vecteurs.3ème vecteur
>c(sam+sam)
>c(2,4,6,
Très bien, mais j'ai l'impression que tu as oublié le 3 exo celui du revenu total par personne.exo 4:
> chef <- c(1200, 1180, 1750, 2100)
>min(chef)
>max(chef)
> chef.na <- c(1200, 1180, 1750, NA)
>min(chef.na,na.rm=TRUE)
>max(chef.na,na.rm=TRUE)
Mais c'était bien, a vrai dire l'idée d'utiliser un vecteur dans un autre est une très bonne idée, ça prouve que tu as de bonne approches de programmation, ce qui vas te faciliter l'apprentissage de R.
Et je te demande de motiver un peu les autres personnes aussi, afin que tous le monde participe à cette apprentissage.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Lun 30 Mar - 22:16
Regrouper les commandes dans des scripts
Jusqu’à maintenant nous avons utilisé uniquement la console pour communiquer avec R via l’invite de commandes. Le principal problème de ce mode d’interaction est qu’une fois qu’une commande est tapée, elle est pour ainsi dire « perdue », c’est-à-dire qu’on doit la saisir à nouveau si on veut l’exécuter une seconde fois. L’utilisation de la console est donc restreinte aux petites commandes « jetables », le plus souvent utilisées comme test.
La plupart du temps, les commandes seront stockées dans un fichier à part, que l’on pourra facilement ouvrir, éditer et exécuter en tout ou partie si besoin. On appelle en général ce type de fichier un script.
Pour comprendre comment cela fonctionne, dans le menu Fichier, sélectionnez l’entrée Nouveau script. Une nouvelle fenêtre (vide) apparaît. Nous pouvons désormais y saisir des commandes. Par exemple, tapez sur la première ligne la commande suivante :
2+2
Ensuite, allez dans le menu Éditon, et choisissez Exécuter la ligne ou sélection. Apparement rien ne se passe, mais si vous jetez un oeil à la fenêtre de la console, les lignes suivantes ont dû faire leur apparition :
2 + 2
[1] 4
Voici donc comment soumettre rapidement à R les commandes saisies dans votre fichier. Vous pouvez désormais l’enregistrer, l’ouvrir plus tard, et en exécuter tout ou partie. À noter que vous avez plusieurs possibilités pour soumettre des commandes à R :
– vous pouvez exécuter la ligne sur laquelle se trouve votre curseur en sélectionnant Éditon puis Exécuter la ligne ou sélection, ou plus simplement en appuyant simultanément sur les touches Ctrl et R ;
– vous pouvez sélectionner plusieurs lignes contenant des commandes et les exécuter toutes en une seule fois exactement de la même manière ;
– vous pouvez exécuter d’un coup l’intégralité de votre fichier en choisissant Édition puis Exécuter tout.
La plupart du travail sous R consistera donc à éditer un ou plusieurs fichiers de commandes et à envoyer régulièrement les commandes saisies à R en utilisant les raccourcis clavier ad hoc.
Ajouter des commentaires :
Un commentaire est une ligne ou une portion de ligne qui sera ignorée par R. Ceci signifie qu’on peut y écrire ce qu’on veut, et qu’on va les utiliser pour ajouter tout un tas de commentaires à notre code permettant de décrire les différentes étapes du travail, les choses à se rappeler, les questions en suspens, etc.
Un commentaire sous R commence par un ou plusieurs symboles # (qui s’obtient avec les touches
## Tableau croisé de la CSP par le nombre de livres lus
## Attention au nombre de non réponses !
On peut aussi créer des commentaires pour une ligne en cours :
sam <- 20 # On met 20 dans sam, parce qu'elle le vaut bien
Important: Dans tous les cas, il est très important de documenter ses fichiers R au fur et à mesure, faute de quoi on risque de ne plus y comprendre grand chose si on les reprend ne serait-ce que quelques semaines plus tard.
Tableaux de données :
Dans cette partie nous allons utiliser un jeu de données inclus dans l’extension rgrs.
L'installation de l'extension se fait, comme pour toute extension, en utilisant la commande suivante :
install.packages("rgrs", dep=TRUE) dep =true veut dire que tous les autres extension en relation avec l'extension rgrs vont être téléchargés aussi.
une fenêtre va apparaître pour vous demander de choisir votre miroir de téléchargement, choisissez le pays le plus proche (France).
Ensuite on peut utiliser l'extension de manière classique grâce à l'instruction library en début de session ou de fichier R :
library(rgrs)
Pour mettre à jour, on peut utiliser la fonction update.packages(), qui permet de mettre à jour l'ensemble des extensions installées~:
update.packages()
L’extension rgrs contient plusieurs jeux de données (dataset) destinés à l’apprentissage de R.
hdv2003 est un extrait comportant 2000 individus et 20 variables provenant de l’enquête Histoire de Vie réalisée par l’INSEE en 2003.
L’extrait est tiré du fichier détail mis à disposition librement (ainsi que de nombreux autres) par l’INSEE à l’adresse suivante :
http://www.insee.fr/fr/themes/detail.asp?ref_id=fd-HDV03
Les variables retenues ont été parfois partiellement recodées. La liste des variables est la suivante :

Pour pouvoir utiliser ces données, il faut d’abord charger l’extension rgrs (après l’avoir installée, bien entendu) :
> library(rgrs)
Puis indiquer à R que nous souhaitons accéder au jeu de données à l’aide de la commande data :
> data(hdv2003)
Bien. Et maintenant, elles sont où mes données ? Et bien elles se trouvent dans un objet nommé hdv2003 désormais accessible directement. Essayons de taper son nom à l’invite de commande :
> hdv2003
Le résultat (non reproduit ici) ne ressemble pas forcément à grand-chose. . . Il faut se rappeler que par défaut, lorsqu’on lui fournit seulement un nom d’objet, R essaye de l’afficher de la manière la meilleure (ou la moins pire) possible. La réponse à la commande hdv2003 n’est donc rien moins que l’affichage des données brutes contenues dans cet objet.
Ce qui signifie donc que l’intégralité de notre jeu de données est inclus dans l’objet nommé hdv2003 !
En effet, dans R, un objet peut très bien contenir un simple nombre, un vecteur ou bien le résultat d’une enquête tout entier. Dans ce cas, les objets sont appelés des data frames, ou tableaux de données. Ils peuvent être manipulés comme tout autre objet. Par exemple :
>d <- hdv2003
va entraîner la copie de l’ensemble de nos données dans un nouvel objet nommé d, ce qui peut paraître parfaitement inutile mais a en fait l’avantage de fournir un objet avec un nom beaucoup plus court, ce qui diminuera la quantité de texte à saisir par la suite.
Résumons Comme nous avons désormais décidé de saisir nos commandes dans un script et non plus directement dans la console, les premières lignes de notre fichier de travail sur les données de l’enquête Histoire de vie pourraient donc ressembler à ceci :
## Chargement des extensions nécessaires
library(rgrs)
## Jeu de données hdv2003
data(hdv2003)
d <- hdv2003
Inspecter les données :
Structure du tableau
Avant de travailler sur les données, nous allons essayer de voir à quoi elles ressemblent. Dans notre cas il s’agit de se familiariser avec la stucture du fichier. Lors de l’import de données depuis un autre logiciel, il s’agira souvent de vérifier que l’importation s’est bien déroulée.
Les fonctions nrow, ncol et dim donnent respectivement le nombre de lignes, le nombre de colonnes et les dimensions de notre tableau. Nous pouvons donc d’ores et déjà vérifier que nous avons bien 2000 lignes et 20 colonnes :
> nrow(d)
[1] 2000
> ncol(d)
[1] 20
> dim(d)
[1] 2000 20
La fonction names donne les noms des colonnes de notre tableau, c’est-à-dire les noms des variables :
> names(d)
[1] "id" "age" "sexe" "nivetud"
[5] "poids" "occup" "qualif" "freres.soeurs"
[9] "clso" "relig" "trav.imp" "trav.satisf"
[13] "hard.rock" "lecture.bd" "peche.chasse" "cuisine"
[17] "bricol" "cinema" "sport" "heures.tv"
La fonction str est plus complète. Elle liste les différentes variables, indique leur type et donne le cas échéant des informations supplémentaires ainsi qu’un échantillon des premières valeurs prises par cette variable :
> str(d)
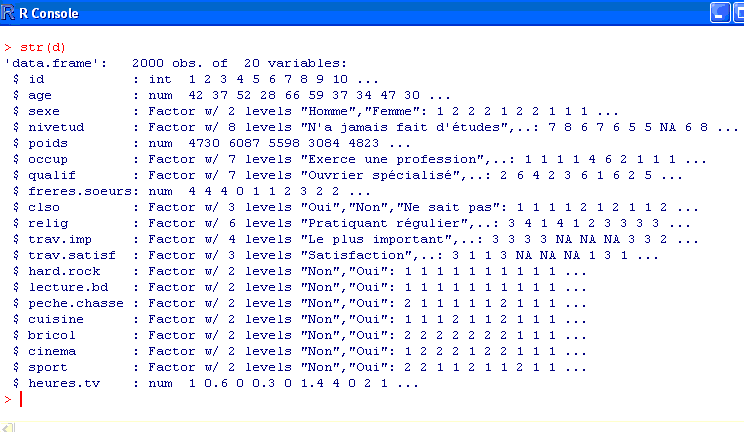
La première ligne nous informe qu’il s’agit bien d’un tableau de données avec 2000 observations et 20 variables. Vient ensuite la liste des variables. La première se nomme id et est de type nombre entier (int). La seconde se nomme age et est de type numérique. La troisième se nomme sexe, il s’agit d’un facteur (factor).
Un facteur et une variable pouvant prendre un nombre limité de modalités (levels). Ici notre variable a deux modalités possibles : Homme et Femme.
Inspection visuelle
La particularité de R par rapport à d’autres logiciels comme Modalisa ou SPSS est de ne pas proposer, par défaut, de vue des données sous forme de tableau. Ceci peut parfois être un peu déstabilisant dans les premiers temps d’utilisation, même si on perd vite l’habitude et qu’on finit par se rendre compte que « voir » les données n’est pas forcément un gage de productivité ou de rigueur dans le traitement.
Néanmoins, R propose une visualisation assez rudimentaire des données sous la forme d’une fenêtre de type tableur, via la fonction edit :
> edit(d)
La fenêtre qui s’affiche permet de naviguer dans le tableau, et même d’éditer le contenu des cases et donc de modifier les données. Lorsque vous fermez la fenêtre, le contenu du tableau s’affiche dans la console : il s’agit en fait du tableau comportant les éventuelles modifications effectuées, d restant inchangé.
Si vous souhaitez appliquer ces modifications, vous pouvez le faire en créant un nouveau tableau :
> d.modif <- edit(d)
ou en remplaçant directement le contenu de d:
> d <- edit(d)
Important : La fonction edit peut être utile pour un avoir un aperçu visuel des données, par contre il est très fortement déconseillé de l’utiliser pour modifier les données. Si on souhaite effectuer des modifications, on remonte en général aux données originales (retouches ponctuelles dans un tableur comme excel par exemple) ou on les effectue à l’aide de commandes (qui seront du coup reproductibles).
Accéder aux variables :
d représente donc l’ensemble de notre tableau de données. Nous avons vu que si l’on saisit simplement d à l’invite de commandes, on obtient un affichage du tableau en question. Mais comment accéder aux variables, c’est à dire aux colonnes de notre tableau ?
La réponse est simple : on utilise le nom de l’objet, suivi de l’opérateur $, suivi du nom de la variable, comme ceci :
> d$sexe
[1] Homme Femme Femme Femme Homme Femme Femme Homme Homme Homme Homme
[12] Homme Homme Femme Femme Homme Homme Homme Femme Femme Femme Homme
[23] Femme Femme Femme Femme Homme Homme Homme Femme Homme Femme Homme
[34] Femme Femme Homme Homme Femme Femme Femme Homme Femme Femme Femme
[45] Homme Femme Homme Homme Femme Homme Homme Homme Homme Homme Femme
[56] Femme Homme Femme Femme Femme Femme Homme Homme Femme Homme Homme
[67] Homme Homme Homme Homme
Levels: Homme Femme
On constate alors que R a bien accédé au contenu de notre variable sexe du tableau d et a affiché son contenu, c’est-à-dire l’ensemble des valeurs prises par la variable.
Les fonctions head et tail permettent d’afficher seulement les premières (respectivement les dernières) valeurs prises par la variable. On peut leur passer en argument le nombre d’éléments à afficher :
> head(d$sport)
[1] Oui Oui Non Non Oui Non
Levels: Non Oui
> tail(d$age, 10)
[1] 18 23 71 49 48 20 46 26 52 48
A noter que ces fonctions marchent aussi pour afficher les lignes du tableau d :
> head(d, 2)
id age sexe nivetud
1 1 42 Homme Enseignement technique ou professionnel long
2 2 37 Femme Enseignement supérieur y compris technique supérieur
poids occup qualif freres.soeurs clso
1 4730.335 Exerce une profession Ouvrier qualifié 4 Oui
2 6087.447 Exerce une profession Employé 4 Oui
relig trav.imp trav.satisf
1 Appartenance sans pratique Moins important que le reste Equilibre
2 Ni croyance ni appartenance Moins important que le reste Satisfaction
hard.rock lecture.bd peche.chasse cuisine bricol cinema sport heures.tv
1 Non Non Oui Non Oui Non Oui 1.0
2 Non Non Non Non Oui Oui Oui 0.6
------------------------------------------------------------
Ça sera tous pour aujourd'hui en completras demain inchallah et on verra comment analyser les variables et construire des hsitogrammes
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Mar 31 Mar - 21:10
Analyser une variable :
Variable quantitative :
Principaux indicateurs :
Comme la fonction str nous l’a indiqué, notre tableau d contient plusieurs valeurs numériques, dont la variable heures.tv qui représente le nombre moyen passé par les enquêtés à regarder la télévision quotidiennement. On peut essayer de déterminer quelques caractéristiques de cette variable, en utilisant des fonctions déjà vues précédemment :
> mean(d$heures.tv)
[1] NA
> mean(d$heures.tv, na.rm = TRUE)
[1] 2.240240
> sd(d$heures.tv, na.rm = TRUE)
[1] 1.786166
> min(d$heures.tv, na.rm = TRUE)
[1] 0
> max(d$heures.tv, na.rm = TRUE)
[1] 12
> range(d$heures.tv, na.rm = TRUE)
[1] 0 12
On peut lui ajouter la fonction median, qui donne la valeur médiane, et le très utile summary qui donne toutes ces informations ou presque en une seule fois, avec en plus les valeurs des premier et troisième quartiles et le nombre de valeurs manquantes (NA) :
> median(d$heures.tv, na.rm = TRUE)
[1] 2
> summary(d$heures.tv)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 1.00 2.00 2.24 3.00 12.00 2.00
Histogramme :
Tout cela est bien pratique, mais pour pouvoir observer la distribution des valeurs d’une variable quantitative, il n’y a quand même rien de mieux qu’un bon graphique.
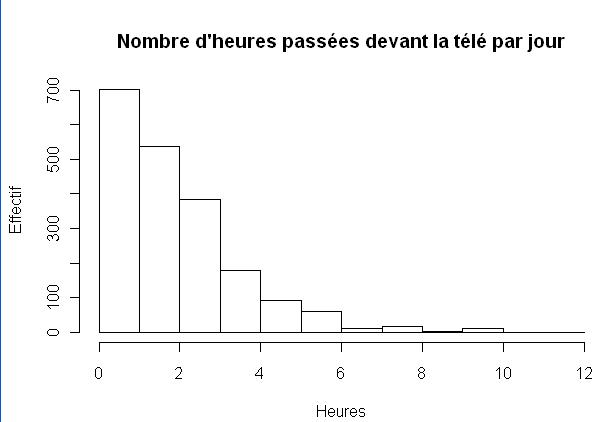
On peut commencer par un histogramme de la répartition des valeurs. Celui-ci peut être généré très facilement avec la fonction hist, comme indiqué figure 3.1 page ci-contre.
Ici, les options main, xlab et ylab permettent de personnaliser le titre du graphique, ainsi que les étiquettes des axes. De nombreuses autres options existent pour personnaliser l’histogramme, parmi celles ci on notera :
probability si elle vaut TRUE, l’histogramme indique la proportion des classes de valeurs au lieu des effectifs.
> hist(d$heures.tv, main = "Nombre d'heures passées devant la télé par jour",
+ xlab = "Heures", ylab = "Effectif")
> hist(d$heures.tv, main = "Heures de télé en 7 classes",
+ breaks = 7, xlab = "Heures", ylab = "Proportion", probability = TRUE,
+ col = "orange")
Remarque : Pour revenir à la fenêtre de la console utiliser le menu fenêtres.
Pour sortir d'un état d'attente + taper ""
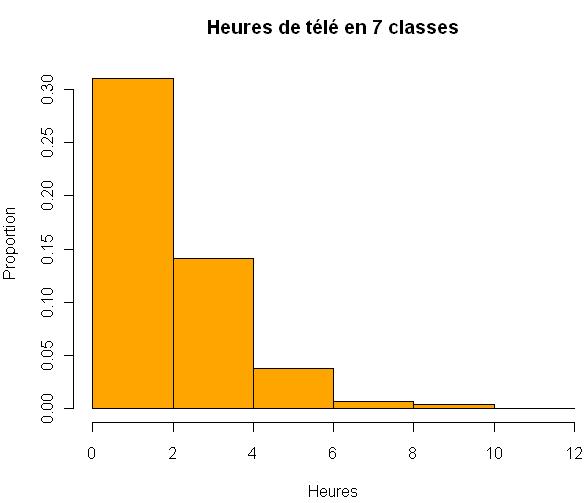
breaks permet de contrôler les classes de valeurs. On peut lui passer un chiffre, qui indiquera alors le nombre de classes, un vecteur, qui indique alors les limites des différentes classes, ou encore une chaîne de caractère ou une fonction indiquant comment les classes doivent être calculées.
col la couleur de l’histogramme. pour une liste exhaustive des couleurs taper colors().
un autre exemple avec des classes spécifiées
> hist(d$heures.tv, main = "Heures de télé avec classes spécifiées",
+ breaks = c(0, 1, 4, 9, 12), xlab = "Heures", ylab = "Proportion",
+ col = "red")

Voir la page d’aide de la fonction hist pour plus de détails sur les différentes options.
Passons maintenant aux boites à moustaches :
>boxplot(d$heures.tv, main = "Nombre d'heures passées devant la télé par\njour",
+ ylab = "Heures")
Noter le \n dans l'argument main, il permet de sauter à la ligne ce qui va permettre à notre titre qui est assez long de figurer sur deux lignes.
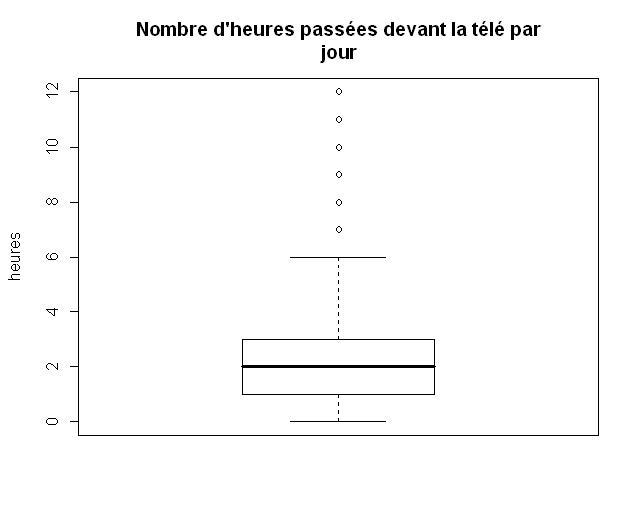
Les boîtes à moustaches, ou boxplot en anglais, sont une autre représentation graphique de la répartition des valeurs d’une variable quantitative. Elles sont particulièrement utiles pour comparer les distributions de plusieurs variables ou d’une même variable entre différents groupes, mais peuvent aussi être utilisées pour représenter la dispersion d’une unique variable. La fonction qui produit ces graphiques est la fonction boxplot.
Comment interpréter ce graphique ? On le comprendra mieux la prochaine fois inchallah.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Mer 1 Avr - 21:52
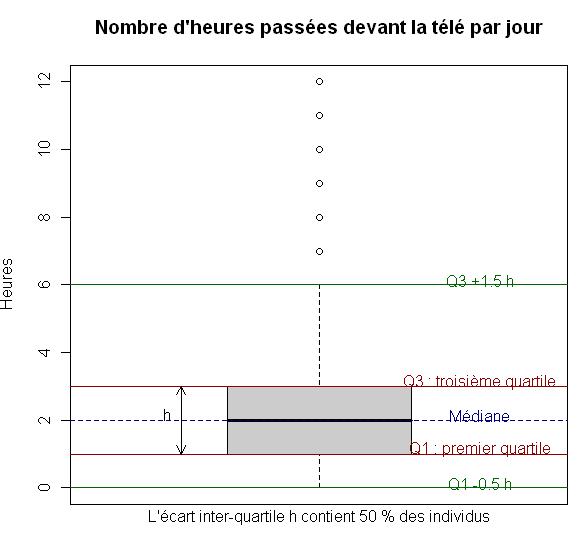
Le carré au centre du graphique est délimité par les premiers et troisième quartiles, avec la médiane représentée par une ligne plus sombre au milieu. Les « fourchettes » s’étendant de part et d’autres vont soit jusqu’à la valeur minimale ou maximale, soit jusqu’à une valeur approximativement égale au quartile le plus proche plus 1,5 fois l’écart inter-quartile. Les points se situant en-dehors de cette fourchette sont représentés par des petits ronds et sont généralement considérés comme des valeurs extrêmes, potentiellement aberrantes.
et si on représenté toute cette explication par un graphique.
on va écrire un programme qui permet d'afficher quelques informations explicatives supplémentaires sur notre boite de moustache, en faite c'est un ensemble d'instructions graphiques qui va afficher des lignes supplémentaires ainsi que du texte à l'intérieur de notre boite à moustache, l'intérêt içi de montrer la flexibilité et la performance de R en terme de production de graphiques personnalisable ce qui est l'un des points fort de R.
1- Affichons une boite à moustache pour la variables heures.tv
boxplot(d$heures.tv, col = grey(0.7), main = "Nombre d'heures passées devant la télé par jour", + ylab = "Heures")
2-Affichons un trait pointillé horizontale qui passe par la médiane
abline(h = median(d$heures.tv, na.rm = TRUE), col = "navy",
+ lty = 2)
3-Affichons le texte médiane à droite du boxplot et et sur le même niveau que la médiane.
text(1.35, median(d$heures.tv, na.rm = TRUE) + 0.15, "Médiane", col = "navy")
4- Affichons une ligne rouge au niveau du 1er quartile et écrire "Q1: premier quartile" en dessus à droite de la boite à moustache.
Q1 <- quantile(d$heures.tv, probs = 0.25, na.rm = TRUE)
abline(h = Q1, col = "darkred")
text(1.35, Q1 + 0.15, "Q1 : premier quartile", col = "darkred",lty = 2)
5- Même chose que 4 mais pour le troisième quartile.
Q3 <- quantile(d$heures.tv, probs = 0.75, na.rm = TRUE)
abline(h = Q3, col = "darkred")
text(1.35, Q3 + 0.15, "Q3 : troisième quartile", col = "darkred", lty = 2)
6- Dessiner une flèche à double sens entre le premier quartile et le 3ème quartile.
arrows(x0 = 0.7, y0 = quantile(d$heures.tv, probs = 0.75, na.rm = TRUE), x1 = 0.7, + y1 = quantile(d$heures.tv, probs = 0.25, na.rm = TRUE), length = 0.1, code = 3)
7- Afficher le texte "H" près de la flèche à double sens.
text(0.7, Q1 + (Q3 - Q1)/2 + 0.15, "h", pos = 2)
8- Afficher le texte suivant "L'écart inter-quartile h contient 50 % des individus" en bas:
mtext("L'écart inter-quartile h contient 50 % des individus", side = 1)
9- Afficher une ligne au dessus de la borne inférieur de la boite à moustache de 0.5 fois l'écart inter quartile et afficher le texte correspondant.
abline(h = Q1 - 0.5 * (Q3 - Q1), col = "darkgreen")
text(1.35, Q1 - 0.5 * (Q3 - Q1) + 0.15, "Q1 -0.5 h", col = "darkgreen", lty = 2)
10- Même chose que 9 mais cette fois avec 1.5 fois l'écart inter quartile en dessus de la borne supérieur.
abline(h = Q3 + 1.5 * (Q3 - Q1), col = "darkgreen")
text(1.35, Q3 + 1.5 * (Q3 - Q1) + 0.15, "Q3 +1.5 h", col = "darkgreen", lty = 2)
Admirons le résultats:
On peut ajouter la représentation des valeurs sur le graphique pour en faciliter la lecture avec des petits traits dessinés sur l’axe vertical
boxplot(d$heures.tv, main = "Nombre d'heures passées devant la télé par\njour", ylab = "Heures")
rug(d$heures.tv, side = 2)

fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Jeu 2 Avr - 1:20
Tris à plat La fonction la plus utilisée pour le traitement et l’analyse des variables qualitatives (variable prenant ses valeurs dans un ensemble de modalités) est sans aucun doute la fonction table, qui donne les effectifs de chaque modalité de la variable.
>table(d$sexe)
Homme Femme
894 1106
Le tableau précédent nous indique que parmi nos enquêtés on trouve 894 hommes et 1106 femmes.
table(d$occup)

Quand le nombre de modalités est élevé, on peut ordonner le tri à plat selon les effectifs à l’aide de la fonction sort.
> sort(table(d$occup))

> sort(table(d$occup), decreasing = TRUE)

À noter que la fonction table exclut par défaut les non-réponses du tableau résultat. L’utilisation de summary permet l’affichage du tri à plat et du nombre de non-réponses :
summary(d$trav.satisf)
Satisfaction Insatisfaction Equilibre NA's
500 109 435 956
Pour obtenir un tableau avec la répartition en pourcentages, on peut utiliser la fonction freq de l’extension rgrs.
> freq(d$qualif)

La colonne n donne les effectifs bruts, et la colonne % la répartition en pourcentages. La fonction accepte plusieurs paramètres permettant d’afficher les totaux, les pourcentages cumulés, de trier selon les effectifs ou de contrôler l’affichage. Par exemple :
freq(d$qualif, cum = TRUE, total = TRUE, sort = "inc", digits = 2,
+ exclude = NA)

La colonne %cum indique ici le pourcentage cumulé, ce qui est ici une très mauvaise idée puisque pour ce type de variable cela n’a aucun sens. Les lignes du tableau résultat ont été triés par effectifs croissants, les totaux ont été ajoutés, les non-réponses exclues, et les pourcentages arrondis à deux décimales.
Pour plus d’informations sur la commande freq, consultez sa page d’aide en ligne avec ?freq ou help("freq").
Représentation graphique :
Pour représenter la répartition des effectifs parmi les modalités d’une variable qualitative, on a souvent tendance à utiliser des diagrammes en secteurs (camemberts). Ceci est possible sous R avec la fonction pie, mais la page d’aide de ladite fonction nous le déconseille assez vivement: les diagrammes en secteur sont en effet une mauvaise manière de présenter ce type d’information, car l’oeil humain préfère comparer des longueurs plutôt que des surfaces.
On privilégiera donc d’autres formes de représentations, à savoir les diagrammes en bâtons et les diagrammes de Cleveland.
Les diagrammes en bâtons sont utilisés automatiquement par R lorsqu’on applique la fonction générique plot à un tri à plat obtenu avec table. On privilégiera cependant ce type de représentations pour les variables de type numérique comportant un nombre fini de valeurs. Le nombre de frères, soeurs, demi-frères et demi-soeurs est un bon exemple.
> plot(table(d$freres.soeurs), main = "Nombre de frères, soeurs, demi-frères et demi-soeurs", ylab = "Effectif")

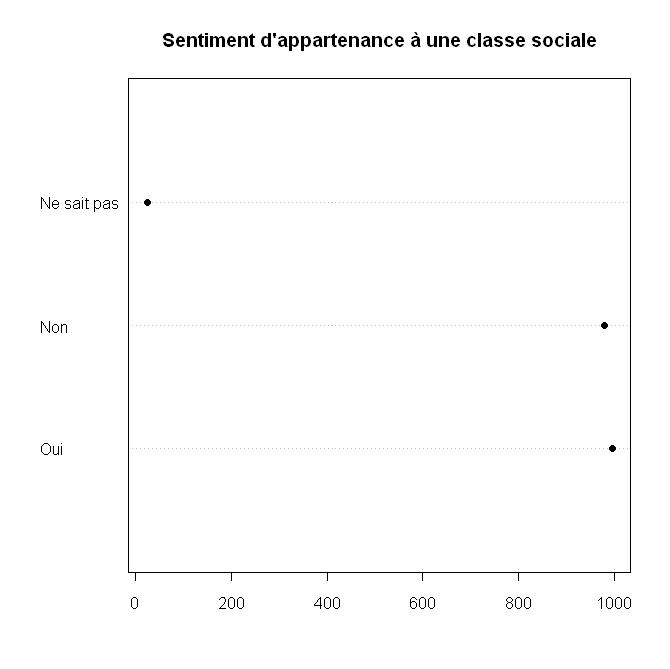
Pour les autres types de variables qualitatives, on privilégiera les diagrammes de Cleveland, obtenus avec la fonction dotchart. On doit appliquer cette fonction au tri à plat de la variable, obtenu avec la fonction table.
> dotchart(table(d$clso), main = "Sentiment d'appartenance à une classe sociale",
+ pch = 19)
Quand la variable comprend un grand nombre de modalités, il est préférable d’ordonner le tri à plat obtenu à l’aide de la fonction sort.
dotchart(sort(table(d$qualif)), main = "Niveau de qualification")
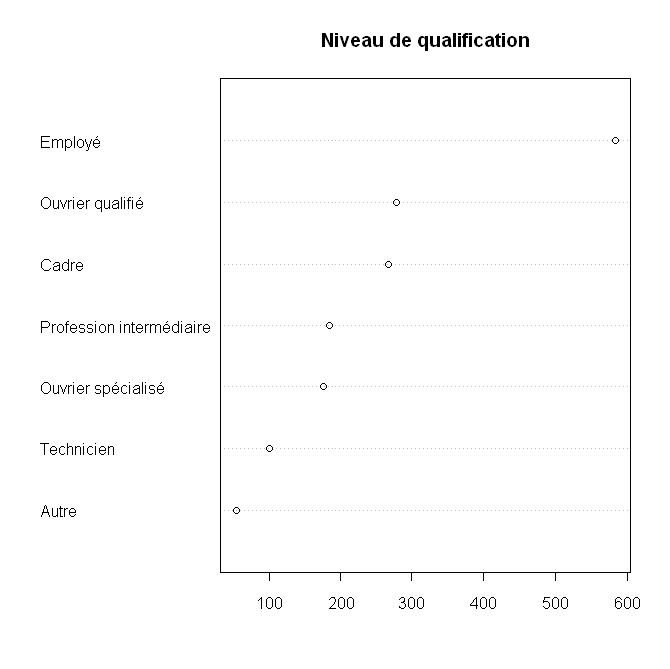
Exercices :
Exercice 5.
Créer un script qui effectue les actions suivantes et exécutez-le :
– charger l’extension rgrs
– charger le jeu de données hdv2003.
– placer le jeu de données dans un objet nommé df
– afficher la liste des variables de df et leur type
Exercice 6.
Des erreurs se sont produites lors de la saisie des données de l’enquête. En fait le premier individu du jeu de données n’a pas 42 ans mais seulement 24, et le second individu n’est pas un homme mais une femme. Corrigez les erreurs et stockez les données corrigées dans un objet nommé df.ok.
Affichez ensuite les 4 premières lignes de df.ok pour vérifier que les modifications ont bien été prises en compte.
Exercice 7.
Nous souhaitons étudier la répartition des âges des enquêtés (variable age). Pour cela, affichez les principaux indicateurs de cette variable. Représentez ensuite sa distribution par un histogramme en 10 classes, puis sous forme de boîte à moustache, et enfin sous la forme d’un diagramme en bâtons représentant les effectifs de chaque âge.
Exercice 8
On s’intéresse maintenant à l’importance accordée par les enquêtés à leur travail (variable trav.imp).
Faites un tri à plat des effectifs des modalités de cette variable avec la commande table. Y’a-t-il des valeurs manquantes ?
Faites un tri à plat affichant à la fois les effectifs et les pourcentages de chaque modalité.
Représentez graphiquement les effectifs des modalités à l’aide d’un diagramme de Cleveland.
--------------------------------------------------------------------------------
Allez un peu de courage tout ce que vous devez savoir pour réaliser ces exercices ce trouve en haut.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Ven 3 Avr - 3:03
voilà je veux importer un fichier excel dans R, j'ai chercher dans le net j'ai essayer d'appliquer les fonction mais je ne sais pas que ce qui ne marche pas
>library(xlsReadWRite)
> tab<-read.table("enssea.xls", header=TRUE, sep="")
et voilà ce qui m'affiche:
Erreur dans file(file, "r") : impossible d'ouvrir la connexion
De plus : Warning message:
In file(file, "r") :
impossible d'ouvrir le fichier 'enssea.xls' : No such file or directory
j'ai essayer aussi:
> tab<-read.xls("enssea")
sa affiche:
Erreur dans read.xls("enssea") :
Unexpected error. Message: Can't find the file "enssea"
et aussi voyant des exemples où ils disent qu'il faut préciser la position du fichier j'ai importée le fichier dans le D et j'ai essayée:
> donnees<-read.xls("D:/enssea")
sa m'affiche:
Erreur dans read.xls("D:/enssea") :
Unexpected error. Message: Can't find the file "D:/enssea"
peux-tu me préciser l'erreur please
samsamo- Bavard
-
Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Ven 3 Avr - 3:55
>library(rgrs)
>data(hdv2003)
>df<-hdv2003
##liste des variable et leurs type
>str(df)
exo6:
##changement de l'âge du 1ier indiv et le sexe du deuxième indiv
>df.modif<-edit(df)
>df.ok<-edit(df)
##affichage des quatre première ligne du tableaudf.ok pour vérifier la correction
>head(df.ok,4)
les deux autres pour 2m1 nechallah ,merci fateh
samsamo- Bavard
-
Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Ven 3 Avr - 15:13
##histogramme de la variable age en 10 classes
>hist(d$age,main="âges des anquêtés en 10 classes",breaks=10,xlab="age",ylab="Effectif",col="blue")
##boîte à moustache représentant la var âge
>boxplot(d$age, main = " âges des enquêtés",ylab="age")
##diagramme en bâton de la var âge
>plot(table(d$age), main = " âges des enquêtés", ylab = "Effectif")
(j'ai pas comprie qcq tu voulais dire par indicateur de la var!!!! c les effectif ou quoi !!)
[b]j'ai remarqué qu'on écrivant la formule de l'histogramme avec (probability=TRUE)ou pas , les effectif changent qcq s'a commme rôle (probability=TRUE)
samsamo- Bavard
-
Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Ven 3 Avr - 15:40
[b]##tri à plat d'effectif de la var trav.imp
table(d$trav.imp)
(oui y'a des valeurs manquante puisque normalement y'en a 2000 obs alors qu'elle ns a afficher que 1044,donc cette fonction ne prend pas les val manquante par considération)
Le plus important Aussi important que le reste
40 254
Moins important que le reste Peu important
700 50
##trie à plat avec la fonction summary
>summary(d$trav.imp)
##affichage des effectif et pourcentage de la var trav.imp
> freq(d$trav.imp)
##diagramme de Cleveland d'effectif de la var trav.imp
> dotchart(table(d$trav.imp),main="",pch=89)
[/b]
samsamo- Bavard
-
Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Ven 3 Avr - 18:15
ceux qu'on obtient avec la fonction summary. donc c summary(d.age)
##diagramme de Cleveland d'effectif de la var trav.imp
> dotchart(table(d$trav.imp),main="",pch=89)
pch=89 c'est pas vraiment ce qu'on appelle un point, en dirais des petits Y et non des points donc il faut mieux utiliser des valeurs qui permettent aux points de bien apparaître son pour autant changer la forme du point ce qui est le cas avec pch=89.
Pour ta question sur l'ouverture du fichier Excel, ça sera l'objet de notre prochain cour inchallah.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par fatehdz Ven 3 Avr - 18:33
L’import et l’export de données depuis ou vers d’autres applications est couvert en détail dans l’un des manuels officiels (en anglais) nommé R Data Import/Export et accessible, comme les autres manuels, à l’adresse suivante : http://cran.r-project.org/manuals.html
Cette partie est très largement tirée de ce document (comme les autres parties d'ailleurs, ils sont tous tirée des documents trouvés sur le net. Vous ne croyez comme même que j'écris de ma tête),et on pourra s’y reporter pour plus de détails.
Important :Un des points délicats pour l’importation de données dans R concerne le nom des variables. Pour être utilisables dans R ceux-ci doivent être à la fois courts et explicites, ce qui n’est pas le cas dans les autres applications statistiques, ou la plupart des fonctions d’importation s’occupent de convertir les noms de manières à ce qu’ils soient compatibles avec les règles de R (remplacement des espaces par des points par exemple), mais un renommage est souvent à prévoir, soit au sein de l’application d’origine, soit une fois les données importées dans R.
Accès aux fichiers et répertoire de travail :
Dans ce qui suit, puisqu’il s’agit d’importer des données externes, nous allons avoir besoin d’accéder à des fichiers situés sur le disque dur de notre ordinateur.
Par exemple, la fonction read.table, très utilisée pour l’import de fichiers texte, prend comme premier argument le nom du fichier à importer, ici fichier.txt
> donnees <- read.table("fichier.txt")
Cependant, ceci ne fonctionnera que si le fichier se trouve dans le répertoire de travail de R. De quoi s’agit-il ? Tout simplement du répertoire dans lequel R est actuellement en train de s’exécuter. Pour savoir quel est le répertoire de travail actuel, on peut utiliser la fonction getwd 1 :
> getwd()
[1] "/home/julien/r/doc/intro"
Sous Windows le chemin du répertoire est souvent un peu compliqué. Vous pouvez alors utiliser la fonction selectwd de l’extension rgrs en tapant rgrs simplement
> selectwd()
Une boîte de dialogue devrait alors s’afficher vous permettant de sélectionner un répertoire sur votre disque. Sous Windows elle devrait ressembler à ça :

ou vous pouvez simplement changer le dossier de travail en allant dans le menu fichier puis "changer le répertoire courant"
Sélectionnez le répertoire de travail de votre session R est cliquez sur Ok. Vous devriez voir s’afficher le message suivant :
Nouveau repertoire de travail : C:/Documents and Settings/Bureau
Pour automatiser ce changement dans un script, utilisez :
>setwd("C:/Documents and Settings/Bureau")
Si vous travaillez en ligne de commande dans la console, le répertoire de travail a été mis à jour. Si vous travaillez dans un script, il peut être intéressant de rajouter la ligne setwd indiquée précédemment au début de votre script pour automatiser cette opération.
Une fois le répertoire de travail fixé, on pourra accéder aux fichiers qui s’y trouvent directement, en spécifiant seulement leur nom. On peut aussi créer des sous-répertoires dans le répertoire de travail ; une potentielle bonne pratique peut être de regrouper tous les fichiers de données dans un sous-répertoire
nommé donnees. On pourra alors accéder aux fichiers qui s’y trouvent de la manière suivante :
> donnees <- read.table("donnees/fichier.txt")
Dans ce qui suit on supposera que les fichiers à importer se trouvent directement dans le répertoire de travail, et on n’indiquera donc que le nom du fichier, sans indication de chemin ou de répertoire supplémentaire.
Import de données depuis un tableur
Il est assez courant de vouloir importer des données saisies ou traitées avec un tableur du type OpenOffice ou Excel. En général les données prennent alors la forme d’un tableau avec les variables en colonne et les individus en ligne.
Depuis Excel :
La démarche pour importer ces données dans R est d’abord de les enregistrer dans un format de type texte. Sous Excel, on peut ainsi sélectionner Fichier, Enregistrer sous, puis dans la zone Type de fichier choisir soit Texte (séparateur tabulation), soit CSV (séparateur : point-virgule).

Dans le premier cas, on peut importer le fichier en utilisant la fonction read.delim2, de la manière suivante :
> donnees <- read.delim2("fichier.txt")
Dans le second cas, on utilise read.csv, de la même manière :
> donnees <- read.csv2("fichier.csv")
Pour plus d'information sur la fonction read reportez vous à l'aide ?read, pour comprendre mieux la différence entre read.csv et read.csv2 et la m^me chose pour read.delim.
Depuis OpenOffice :
Depuis OpenOffice on procédera de la même manière, en sélectionnant le type de fichier Texte CSV.
On importe ensuite les données dans R à l’aide de la fonction read.csv :
> read.csv("fichier.csv", dec = ",")
Autres sources / en cas de problèmes :
Les fonctions read.csv et compagnie sont en fait des dérivées de la fonction plus générique read.table. Celle-ci contient de nombreuses options permettant d’adapter l’import au format du fichier texte. On pourra se reporter à la page d’aide de read.table si on rencontre des problèmes ou si on souhaite importer des fichiers d’autres sources.
Parmi les options disponibles, on citera notamment :
header indique si la première ligne du fichier contient les noms des variables (valeur TRUE) ou non (valeur FALSE).
sep indique le caractère séparant les champs. En général soit une virgule, soit un point-virgule, soit une tabulation. Pour cette dernière l’option est sep="\t".
quote indique le caractère utilisé pour délimiter les champs. En général on utilise soit des guillemets doubles (quote="\"") soit rien du tout (quote="").
dec indique quel est le caractère utilisé pour séparer les nombres et leurs décimales. Il s’agit le plus souvent de la virgule lorsque les applications sont en français (dec=","), et le point pour les programmes anglophones (dec=".").
D’autres options sont disponibles, pour gérer le format d’encodage du fichier source ou de nombreux autres paramètres d’importation. On se réfèrera alors à la page d’aide de read.table et à la section Spreadsheet-like data de R Data Import/Export
Import depuis d’autres logiciels :
La plupart des fonctions permettant l’import de fichiers de données issus d’autres logiciels font partie d’une extension nommée foreign, présente à l’installation de R mais qu’il est nécessaire de charger en mémoire avant utilisation avec l’instruction :
> library(foreign)
SAS :
Les fichiers au format SAS se présentent en général sous deux format : format SAS export (extension .xport ou .xpt) ou format SAS natif (extension .sas7bdat).
R peut lire directement les fichiers au format export via la fonction read.xport de l’extension foreign.
Celle-ci s’utilise très simplement, en lui passant le nom du fichier en argument :
> donnees <- read.xport("fichier.xpt")
En ce qui concerne les fichiers au format SAS natif, il existe des fonctions permettant de les importer, mais elles nécessitent d’avoir une installation de SAS fonctionnelle sur sa machine (il s’agit des fonctions read.ssd de l’extension foreign, et sas.get de l’extension Hmisc).
Si on ne dispose que des fichiers au format SAS natif, le plus simple est d’utiliser l’application SAS System Viewer, qui permet de lire des fichiers SAS natif, de les visualiser et de les enregistrer au format export ou dans un format texte. Cette application est téléchargeable gratuitement, mais ne fonctionne
que sous Windows 3 :
http://www.umass.edu/statdata/software/downloads/SASViewer/
SPSS
Les fichiers générés par SPSS sont accessibles depuis R avec la fonction read.spss de l’extension foreign. Celle-ci peut lire aussi bien les fichiers sauvegardés avec la fonction Enregistrer que ceux générés par la fonction Exporter.
La syntaxe est également très simple :
> donnees <- read.spss("fichier.sav")
Plusieurs options permettant de contrôler l’importation des données sont disponibles. On se reportera à la page d’aide de la fonction pour plus d’informations.
Modalisa :
L’extension rgrs fournit plusieurs fonctions pour l’import ou l’export de données depuis ou rgrs vers Modalisa et pour leur traitement, en particulier concernant les questions à réponses multiples.
L’import de données permet de récupérer des sauvegardes au format ASCII et s’appuie sur la fonction mls.import.
On trouvera davantage d’informations à l’adresse suivante :
http://alea.fr.eu.org/j/rgrs_modalisa.html
Fichiers dbf :
L’Insee diffuse ses fichiers détails depuis son site Web au format dBase (extension .dbf). Ceux-ci sont directement lisibles dans R avec la fonction read.dbf de l’extension foreign.
> donnees <- read.dbf("fichier.dbf")
La principale limitation des fichiers dbf est de ne pas gérer plus de 256 colonnes. Les tables des enquêtes de l’Insee sont donc parfois découpées en plusieurs fichiers dbf qu’il convient de fusionner avec
la fonction merge. L’utilisation de cette fonction sera détaillée ultérieurement
Autres sources :
R offre de très nombreuses autres possibilités pour accéder aux données. Il est ainsi possible d’importer des données depuis d’autres applications qui n’ont pas été évoquées (Stata, S-Plus, etc.), de se connecter à un système de base de données relationelle type MySql, de lire des données via ODBC ou des connexions
réseau, etc.
Pour plus d’informations on consultera le manuel R Data Import/Export :
http://cran.r-project.org/manuals.html
Exporter des données :
R propose également différentes fonctions permettant d’exporter des données vers des formats variés.
– write.table est l’équivalent de read.table et permet d’enregistrer des tableaux de données au format texte, avec de nombreuses options ;
– write.foreign, de l’extension foreign, permet d’exporter des données aux formats SAS, SPSS ou Stata ;
– write.dbf, de l’extension foreign, permet d’exporter des données au format dBase ; rgrs
– mls.export, de l’extension rgrs, permet d’exporter des données à destination de Modalisa ;
– save permet d’enregistrer des objets R sur le disque pour récupération ultérieure ou sur un autre système.
À nouveau, pour plus de détails on se référera aux pages d’aide de ces fonctions et au manuel R Data Import/Export.
Exercices :
Exercice 9
Saisissez quelques données fictives dans une application de type tableur, enregistrez-les dans un format texte et importez-les dans R.
Vérifiez que l’importation s’est bien déroulée.
Exercice 10
L’adresse suivante permet de télécharger un fichier au format dBase contenant une partie des données de l’enquête EPCV Vie associative de l’INSEE (2002) :
http://telechargement.insee.fr/fichiersdetail/epcv1002/dbase/epcv1002_BENEVOLAT_dbase.zip
Téléchargez le fichier, décompressez-le et importez les données dans R.
fatehdz- Bavard
-
Nombre de messages : 273
Age : 41
Localisation : Alger
Emploi/loisirs : Statisticien
Date d'inscription : 24/11/2007 -
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Sam 4 Avr - 19:16
et pour le pch , je ne savais pas que c'était nécessaire la forme ronde des points
merci encore
samsamo- Bavard
-
Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par samsamo Mer 8 Avr - 1:25
>library(foreign)
>ss<-read.dbf("benevolat.dbf")
>ss
un petit aperçue de ce que sa affiche
415 2 1 2 2 2 2 2 2 2
416
##affichage du tableau
>edit(ss)
résolution exo 9:
>sss<-read.delim2("inps.txt")
>sss
un aperçue
nom prénom sexe situationf emploi salaire
1 aaa sss f m fonctionn 2000
2 zzz bbb h c fonctionn 2000
[b]je veux savoir svp que ce qui est préférable de travailler avec la console ou script !!! puisque qd je tape une formule ds le script et je fais exécuter elle m'affiche la formule ds la console alors je croix qu'il vaut mieux travailler directement avec la console non !!!!!
samsamo- Bavard
-
Nombre de messages : 279
Age : 34
Localisation : chez mon père
Emploi/loisirs : vivre
Date d'inscription : 15/09/2008
Re: Apprendre "R" un logiciel statistique gratuit
par Calling Ven 17 Avr - 18:45
Langage R.pdf - 0.55MB
Bonne lecture

Calling- Bavard
-
Nombre de messages : 270
Age : 38
Localisation : Devant mon PC
Emploi/loisirs : sport,musique,ciné,net.......etc
Date d'inscription : 30/09/2007
Re: Apprendre "R" un logiciel statistique gratuit
par mohamoha Lun 10 Jan - 19:00
MERCI
mohamoha- Timide

-
Nombre de messages : 6
Age : 58
Date d'inscription : 10/01/2011
Re: Apprendre "R" un logiciel statistique gratuit
par onlystyle Mer 12 Jan - 0:02
j'ai eu l'occasion d'avoir besoin d'un tel logiciel c'était dans l'ajustement de données sur des loi de probabilités dans mon cas sur binomiale négative mais en fin de compte j'ai pas eu assez de documentation pour continuer avec
un autre logiciel a pu répondre a ma problématique qui est limdep

onlystyle- Bavard chevronné

-
Nombre de messages : 692
Age : 38
Date d'inscription : 14/11/2007
Re: Apprendre "R" un logiciel statistique gratuit
par mohamoha Dim 16 Jan - 12:35
je souhaite que quelqu'un puisse parler des fonctions de R et dans le sujet de l'analyse spatial et la fonction Ripley.
merci
mohamoha- Timide
-
Nombre de messages : 6
Age : 58
Date d'inscription : 10/01/2011
Re: Apprendre "R" un logiciel statistique gratuit
par mohamoha Dim 16 Jan - 12:40
mohamoha- Timide
-
Nombre de messages : 6
Age : 58
Date d'inscription : 10/01/2011
Re: Apprendre "R" un logiciel statistique gratuit
par mohamoha Jeu 27 Jan - 16:42
Merci
mohamoha- Timide
-
Nombre de messages : 6
Age : 58
Date d'inscription : 10/01/2011
Re: Apprendre "R" un logiciel statistique gratuit
par mohamoha Jeu 27 Jan - 16:44
mohamoha- Timide
-
Nombre de messages : 6
Age : 58
Date d'inscription : 10/01/2011
» Apprendre Access (les Tables)
» Apprendre Crystal Xcelsius
» Apprendre Access "Les Formulaires"
» Skypecast statistique et informatique decisionnelle
|
|
|